Las pruebas ICFES son exámenes estandarizados obligatorios en Colombia, siendo la principal la Saber 11 que evalúa competencias en lectura crítica, matemáticas, ciencias naturales, sociales e inglés. Son fundamentales porque constituyen un requisito para graduarse de bachillerato, determinan el acceso a universidades públicas, sirven como criterio para becas, permiten evaluar la calidad educativa de las instituciones y orientan las políticas públicas del sistema educativo nacional
Impacto del cierre de escuelas por COVID-19
Este análisis implica examinar los datos históricos de los resultados de la prueba Saber 11 en los colegios públicos de Bogotá y compararlos con los resultados durante el cierre de las escuelas con el propósito de identificar los cambios y las tendencias que pueden haber ocurrido durante este periodo. Además, se llevará a cabo un análisis comparativo de las diferentes localidades de Bogotá para determinar si existen diferencias significativas en los resultados de la prueba Saber 11 entre los colegios públicos de la ciudad y para finalizar se hará una reflexión sobre cómo la educación remota afectó a los estudiantes de los colegios públicos en Bogotá que son primordialmente los de menores condiciones socioeconómicas y si estos tuvieron acceso o no, a recursos educativos y tecnológicos adecuados durante la pandemia.
Es importante destacar que los cambios mencionados anteriormente se refieren a las diferencias en los puntajes promedio según algunas variables de interés, entre las cuales se incluyen:
-
Ubicación geográfica (localidad donde se encuentra la institución educativa oficial).
-
Estrato socioeconómico de los estudiantes
-
Jornada académica en la que se encuentra el estudiante
-
Disponibilidad o no de un computador en el hogar.
-
Acceso o no a internet en el hogar.
-
Nivel educativo de los padres.
-
Flexibilización de los contenidos curriculares desarrollados, asociados a intensidad horaria, metodologías implementadas y criterios de evaluación.
Seguiremos estas etapas, para la primera etapa analizaremos, importaremos los datos, haremos correciones y revisaremos que todo este bien para poder empezar con lo divertido, es muy normal que en empresas a inicio existan errores, mala organizacion, malas decisiones, información decentralizada, etc. Cosas que iremos arreglando, por ejemplo, para este escenario trabajaremos con txts proporcionados de la base de datos del icfes. Una vez que hagamos los analisis necesarios y las graficas necesarias haremos los entrenamientos, validamos y realizaremos la prediccion con algoritmos de aprendizaje supervizado - y predicciones con algebra linel multiple.
1. Importanción de Pandas.
A mededida que se escribe este analisis iremos importando las librerias (Un conjunto de funciones y herramientas predefinidas que pueden ser importadas y utilizadas en el desarrollo para realizar tareas específicas). Para este paso usaremos pandas para el analisis y manipulacion de datos.
import pandas as pd1.1 Identificación de datos.
En este proceso analizaremos las variables e importaremos el dataset (archivos.txt) de la base de datos proporcionada del ICFEs, como sabemos los csv tienen separadores para identificar columnas, filas y datos, en este caso si visualizamos alguno de estos archivos tenemos ¬ como separador. Así que no hace falta la conversion aun csv.
import pandas as pd
path = '/content/drive/MyDrive/icfes/'
# Importamos los datos a nuestra variable df
df = pd.read_csv(path+'SB11_20181.TXT', sep='¬', engine='python')
df.head()| ESTU_TIPODOCUMENTO | ESTU_NACIONALIDAD | ESTU_GENERO | ESTU_FECHANACIMIENTO | PERIODO | ESTU_CONSECUTIVO | ESTU_ESTUDIANTE | ESTU_PAIS_RESIDE | ESTU_TIENEETNIA | ESTU_ETNIA | ... | PUNT_INGLES | PERCENTIL_INGLES | DESEMP_INGLES | PUNT_GLOBAL | PERCENTIL_GLOBAL | ESTU_INSE_INDIVIDUAL | ESTU_NSE_INDIVIDUAL | ESTU_NSE_ESTABLECIMIENTO | ESTU_ESTADOINVESTIGACION | ESTU_PILOPAGA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | TI | COLOMBIA | F | 19/07/2000 | 20181 | SB11201810005035 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 44 | 21 | A- | 226 | 20 | 54.101344 | NSE3 | 3.0 | PUBLICAR | NO |
| 1 | TI | COLOMBIA | M | 03/10/2001 | 20181 | SB11201810005012 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 58 | 45 | A2 | 263 | 37 | 66.990405 | NSE4 | 3.0 | PUBLICAR | NO |
| 2 | TI | COLOMBIA | F | 29/06/2000 | 20181 | SB11201810005026 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 32 | 5 | A- | 204 | 12 | 45.721848 | NSE2 | 3.0 | PUBLICAR | NO |
| 3 | TI | COLOMBIA | M | 30/04/2001 | 20181 | SB11201810004998 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 50 | 32 | A1 | 331 | 70 | 51.145124 | NSE2 | 3.0 | PUBLICAR | NO |
| 4 | TI | COLOMBIA | F | 06/08/2001 | 20181 | SB11201810005010 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 62 | 50 | A2 | 318 | 63 | 53.365582 | NSE3 | 3.0 | PUBLICAR | NO |
5 rows × 82 columns
df| ESTU_TIPODOCUMENTO | ESTU_NACIONALIDAD | ESTU_GENERO | ESTU_FECHANACIMIENTO | PERIODO | ESTU_CONSECUTIVO | ESTU_ESTUDIANTE | ESTU_PAIS_RESIDE | ESTU_TIENEETNIA | ESTU_ETNIA | ... | PUNT_INGLES | PERCENTIL_INGLES | DESEMP_INGLES | PUNT_GLOBAL | PERCENTIL_GLOBAL | ESTU_INSE_INDIVIDUAL | ESTU_NSE_INDIVIDUAL | ESTU_NSE_ESTABLECIMIENTO | ESTU_ESTADOINVESTIGACION | ESTU_PILOPAGA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | TI | COLOMBIA | F | 19/07/2000 | 20181 | SB11201810005035 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 44 | 21 | A- | 226 | 20 | 54.101344 | NSE3 | 3.0 | PUBLICAR | NO |
| 1 | TI | COLOMBIA | M | 03/10/2001 | 20181 | SB11201810005012 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 58 | 45 | A2 | 263 | 37 | 66.990405 | NSE4 | 3.0 | PUBLICAR | NO |
| 2 | TI | COLOMBIA | F | 29/06/2000 | 20181 | SB11201810005026 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 32 | 5 | A- | 204 | 12 | 45.721848 | NSE2 | 3.0 | PUBLICAR | NO |
| 3 | TI | COLOMBIA | M | 30/04/2001 | 20181 | SB11201810004998 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 50 | 32 | A1 | 331 | 70 | 51.145124 | NSE2 | 3.0 | PUBLICAR | NO |
| 4 | TI | COLOMBIA | F | 06/08/2001 | 20181 | SB11201810005010 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 62 | 50 | A2 | 318 | 63 | 53.365582 | NSE3 | 3.0 | PUBLICAR | NO |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12522 | TI | COLOMBIA | M | 09/04/2000 | 20181 | SB11201810055305 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 51 | 33 | A1 | 208 | 13 | 71.165216 | NSE4 | 2.0 | PUBLICAR | NO |
| 12523 | TI | COLOMBIA | F | 17/12/2001 | 20181 | SB11201810055294 | ESTUDIANTE | COLOMBIA | Si | NaN | ... | 46 | 25 | A- | 260 | 35 | 55.447884 | NSE3 | 2.0 | PUBLICAR | NO |
| 12524 | TI | COLOMBIA | M | 27/03/2000 | 20181 | SB11201810055303 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 26 | 1 | A- | 210 | 14 | 62.192852 | NSE3 | 2.0 | PUBLICAR | NO |
| 12525 | TI | COLOMBIA | M | 18/01/2002 | 20181 | SB11201810055301 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 44 | 21 | A- | 215 | 16 | 54.766308 | NSE3 | 2.0 | PUBLICAR | NO |
| 12526 | TI | COLOMBIA | M | 04/05/2001 | 20181 | SB11201810055300 | ESTUDIANTE | COLOMBIA | No | NaN | ... | 42 | 18 | A- | 278 | 44 | 53.387778 | NSE3 | 2.0 | PUBLICAR | NO |
12527 rows × 82 columns
Tenemos 82 columnas y 12mil estudiantes, y vimos ejemplos de como se reflejan los datos de los estudiantes, ya nos podemos dar una idea de como manejar las variables categóricas, por ejemplo, ESTU_GENERO, donde utilizaremos One-Hot Encoding, donde se crea una nueva columna binaria (0 o 1) para cada categoría única de la variable.
- F: Femenino (0)
- M: Mascuino (1)
Pero sin adelantarnos, sigamos estudiando las variables ya que no se muestran todas.
df.info()RangeIndex: 12527 entries, 0 to 12526
Data columns (total 82 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ESTU_TIPODOCUMENTO 12527 non-null object
1 ESTU_NACIONALIDAD 12527 non-null object
2 ESTU_GENERO 12527 non-null object
3 ESTU_FECHANACIMIENTO 12527 non-null object
4 PERIODO 12527 non-null int64
5 ESTU_CONSECUTIVO 12527 non-null object
6 ESTU_ESTUDIANTE 12527 non-null object
7 ESTU_PAIS_RESIDE 12527 non-null object
8 ESTU_TIENEETNIA 12526 non-null object
9 ESTU_ETNIA 119 non-null object
10 ESTU_DEPTO_RESIDE 12527 non-null object
11 ESTU_COD_RESIDE_DEPTO 12527 non-null int64
12 ESTU_MCPIO_RESIDE 12527 non-null object
13 ESTU_COD_RESIDE_MCPIO 12527 non-null int64
14 FAMI_ESTRATOVIVIENDA 12063 non-null object
15 FAMI_PERSONASHOGAR 12244 non-null object
16 FAMI_CUARTOSHOGAR 12319 non-null object
17 FAMI_EDUCACIONPADRE 12094 non-null object
18 FAMI_EDUCACIONMADRE 12096 non-null object
19 FAMI_TRABAJOLABORPADRE 12273 non-null object
20 FAMI_TRABAJOLABORMADRE 12299 non-null object
21 FAMI_TIENEINTERNET 12108 non-null object
22 FAMI_TIENESERVICIOTV 12083 non-null object
23 FAMI_TIENECOMPUTADOR 12347 non-null object
24 FAMI_TIENELAVADORA 12354 non-null object
25 FAMI_TIENEHORNOMICROOGAS 12347 non-null object
26 FAMI_TIENEAUTOMOVIL 12329 non-null object
27 FAMI_TIENEMOTOCICLETA 12317 non-null object
28 FAMI_TIENECONSOLAVIDEOJUEGOS 12335 non-null object
29 FAMI_NUMLIBROS 12102 non-null object
30 FAMI_COMELECHEDERIVADOS 12086 non-null object
31 FAMI_COMECARNEPESCADOHUEVO 12073 non-null object
32 FAMI_COMECEREALFRUTOSLEGUMBRE 12076 non-null object
33 FAMI_SITUACIONECONOMICA 12328 non-null object
34 ESTU_DEDICACIONLECTURADIARIA 12091 non-null object
35 ESTU_DEDICACIONINTERNET 12069 non-null object
36 ESTU_HORASSEMANATRABAJA 12326 non-null object
37 ESTU_TIPOREMUNERACION 12273 non-null object
38 COLE_CODIGO_ICFES 12527 non-null int64
39 COLE_COD_DANE_ESTABLECIMIENTO 12527 non-null int64
40 COLE_NOMBRE_ESTABLECIMIENTO 12527 non-null object
41 COLE_GENERO 12527 non-null object
42 COLE_NATURALEZA 12527 non-null object
43 COLE_CALENDARIO 12527 non-null object
44 COLE_BILINGUE 11123 non-null object
45 COLE_CARACTER 12403 non-null object
46 COLE_COD_DANE_SEDE 12527 non-null int64
47 COLE_NOMBRE_SEDE 12527 non-null object
48 COLE_SEDE_PRINCIPAL 12527 non-null object
49 COLE_AREA_UBICACION 12527 non-null object
50 COLE_JORNADA 12527 non-null object
51 COLE_COD_MCPIO_UBICACION 12527 non-null int64
52 COLE_MCPIO_UBICACION 12527 non-null object
53 COLE_COD_DEPTO_UBICACION 12527 non-null int64
54 COLE_DEPTO_UBICACION 12527 non-null object
55 ESTU_PRIVADO_LIBERTAD 12527 non-null object
56 ESTU_COD_MCPIO_PRESENTACION 12527 non-null int64
57 ESTU_MCPIO_PRESENTACION 12527 non-null object
58 ESTU_DEPTO_PRESENTACION 12527 non-null object
59 ESTU_COD_DEPTO_PRESENTACION 12527 non-null int64
60 PUNT_LECTURA_CRITICA 12527 non-null int64
61 PERCENTIL_LECTURA_CRITICA 12527 non-null int64
62 DESEMP_LECTURA_CRITICA 12527 non-null int64
63 PUNT_MATEMATICAS 12527 non-null int64
64 PERCENTIL_MATEMATICAS 12527 non-null int64
65 DESEMP_MATEMATICAS 12527 non-null int64
66 PUNT_C_NATURALES 12527 non-null int64
67 PERCENTIL_C_NATURALES 12527 non-null int64
68 DESEMP_C_NATURALES 12527 non-null int64
69 PUNT_SOCIALES_CIUDADANAS 12527 non-null int64
70 PERCENTIL_SOCIALES_CIUDADANAS 12527 non-null int64
71 DESEMP_SOCIALES_CIUDADANAS 12527 non-null int64
72 PUNT_INGLES 12527 non-null int64
73 PERCENTIL_INGLES 12527 non-null int64
74 DESEMP_INGLES 12527 non-null object
75 PUNT_GLOBAL 12527 non-null int64
76 PERCENTIL_GLOBAL 12527 non-null int64
77 ESTU_INSE_INDIVIDUAL 12268 non-null float64
78 ESTU_NSE_INDIVIDUAL 12268 non-null object
79 ESTU_NSE_ESTABLECIMIENTO 12430 non-null float64
80 ESTU_ESTADOINVESTIGACION 12527 non-null object
81 ESTU_PILOPAGA 12527 non-null object
dtypes: float64(2), int64(26), object(54)
memory usage: 7.8+ MB
1.2 Categorización de variables por grupos
Categoría 1: Información personal del estudiante
- ESTU_TIPODOCUMENTO
- ESTU_NACIONALIDAD
- ESTU_GENERO
- ESTU_FECHANACIMIENTO
- ESTU_CONSECUTIVO
- ESTU_ESTUDIANTE
- ESTU_PAIS_RESIDE
- ESTU_TIENEETNIA
- ESTU_ETNIA
- ESTU_DEPTO_RESIDE
- ESTU_COD_RESIDE_DEPTO
- ESTU_MCPIO_RESIDE
- ESTU_COD_RESIDE_MCPIO
- ESTU_PRIVADO_LIBERTAD
Categoría 2: Información familiar y socioeconómica
- FAMI_ESTRATOVIVIENDA
- FAMI_PERSONASHOGAR
- FAMI_CUARTOSHOGAR
- FAMI_EDUCACIONPADRE
- FAMI_EDUCACIONMADRE
- FAMI_TRABAJOLABORPADRE
- FAMI_TRABAJOLABORMADRE
- FAMI_TIENEINTERNET
- FAMI_TIENESERVICIOTV
- FAMI_TIENECOMPUTADOR
- FAMI_TIENELAVADORA
- FAMI_TIENEHORNOMICROOGAS
- FAMI_TIENEAUTOMOVIL
- FAMI_TIENEMOTOCICLETA
- FAMI_TIENECONSOLAVIDEOJUEGOS
- FAMI_NUMLIBROS
- FAMI_COMELECHEDERIVADOS
- FAMI_COMECARNEPESCADOHUEVO
- FAMI_COMECEREALFRUTOSLEGUMBRE
- FAMI_SITUACIONECONOMICA
- ESTU_INSE_INDIVIDUAL
- ESTU_NSE_INDIVIDUAL
- ESTU_NSE_ESTABLECIMIENTO
Categoría 3: Información académica y laboral del estudiante
- ESTU_DEDICACIONLECTURADIARIA
- ESTU_DEDICACIONINTERNET
- ESTU_HORASSEMANATRABAJA
- ESTU_TIPOREMUNERACION
- ESTU_ESTADOINVESTIGACION
- ESTU_PILOPAGA
Categoría 4: Información del colegio
- COLE_CODIGO_ICFES
- COLE_COD_DANE_ESTABLECIMIENTO
- COLE_NOMBRE_ESTABLECIMIENTO
- COLE_GENERO
- COLE_NATURALEZA
- COLE_CALENDARIO
- COLE_BILINGUE
- COLE_CARACTER
- COLE_COD_DANE_SEDE
- COLE_NOMBRE_SEDE
- COLE_SEDE_PRINCIPAL
- COLE_AREA_UBICACION
- COLE_JORNADA
- COLE_COD_MCPIO_UBICACION
- COLE_MCPIO_UBICACION
- COLE_COD_DEPTO_UBICACION
- COLE_DEPTO_UBICACION
Categoría 5: Información de la presentación del examen
- PERIODO
- ESTU_COD_MCPIO_PRESENTACION
- ESTU_MCPIO_PRESENTACION
- ESTU_DEPTO_PRESENTACION
- ESTU_COD_DEPTO_PRESENTACION
Categoría 6: Resultados de la prueba Saber 11
- PUNT_LECTURA_CRITICA
- PERCENTIL_LECTURA_CRITICA
- DESEMP_LECTURA_CRITICA
- PUNT_MATEMATICAS
- PERCENTIL_MATEMATICAS
- DESEMP_MATEMATICAS
- PUNT_C_NATURALES
- PERCENTIL_C_NATURALES
- DESEMP_C_NATURALES
- PUNT_SOCIALES_CIUDADANAS
- PERCENTIL_SOCIALES_CIUDADANAS
- DESEMP_SOCIALES_CIUDADANAS
- PUNT_INGLES
- PERCENTIL_INGLES
- DESEMP_INGLES
- PUNT_GLOBAL
- PERCENTIL_GLOBAL
# Consultamos datos estadisticos generales: numeros de elementos, media, desviación, valor minimo, porcentajes
df.describe().transpose()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| PERIODO | 12527.0 | 2.018100e+04 | 0.000000e+00 | 2.018100e+04 | 2.018100e+04 | 2.018100e+04 | 2.018100e+04 | 2.018100e+04 |
| ESTU_COD_RESIDE_DEPTO | 12527.0 | 4.790053e+01 | 3.109914e+01 | 5.000000e+00 | 1.100000e+01 | 7.600000e+01 | 7.600000e+01 | 7.600000e+01 |
| ESTU_COD_RESIDE_MCPIO | 12527.0 | 4.796111e+04 | 3.111927e+04 | 5.001000e+03 | 1.100100e+04 | 7.600100e+04 | 7.600100e+04 | 7.689500e+04 |
| COLE_CODIGO_ICFES | 12527.0 | 8.921620e+04 | 1.367315e+05 | 1.820000e+02 | 1.934900e+04 | 4.644100e+04 | 1.061200e+05 | 7.146340e+05 |
| COLE_COD_DANE_ESTABLECIMIENTO | 12527.0 | 3.577158e+11 | 4.197414e+10 | 1.765200e+11 | 3.118480e+11 | 3.760010e+11 | 3.760010e+11 | 4.768921e+11 |
| COLE_COD_DANE_SEDE | 12527.0 | 3.576174e+11 | 4.195383e+10 | 1.765200e+11 | 3.118480e+11 | 3.760010e+11 | 3.760010e+11 | 4.768921e+11 |
| COLE_COD_MCPIO_UBICACION | 12527.0 | 4.849935e+04 | 3.063171e+04 | 5.001000e+03 | 1.100100e+04 | 7.600100e+04 | 7.600100e+04 | 7.689200e+04 |
| COLE_COD_DEPTO_UBICACION | 12527.0 | 4.839650e+01 | 3.064030e+01 | 5.000000e+00 | 1.100000e+01 | 7.600000e+01 | 7.600000e+01 | 7.600000e+01 |
| ESTU_COD_MCPIO_PRESENTACION | 12527.0 | 4.790827e+04 | 3.118285e+04 | 5.001000e+03 | 1.100100e+04 | 7.600100e+04 | 7.600100e+04 | 7.683400e+04 |
| ESTU_COD_DEPTO_PRESENTACION | 12527.0 | 4.785280e+01 | 3.117389e+01 | 5.000000e+00 | 1.100000e+01 | 7.600000e+01 | 7.600000e+01 | 7.600000e+01 |
| PUNT_LECTURA_CRITICA | 12527.0 | 6.426591e+01 | 9.022561e+00 | 2.900000e+01 | 5.900000e+01 | 6.500000e+01 | 7.100000e+01 | 1.000000e+02 |
| PERCENTIL_LECTURA_CRITICA | 12527.0 | 6.320029e+01 | 2.453513e+01 | 1.000000e+00 | 4.500000e+01 | 6.600000e+01 | 8.400000e+01 | 1.000000e+02 |
| DESEMP_LECTURA_CRITICA | 12527.0 | 3.409675e+00 | 6.386825e-01 | 1.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 | 4.000000e+00 |
| PUNT_MATEMATICAS | 12527.0 | 6.379428e+01 | 1.189882e+01 | 2.100000e+01 | 5.600000e+01 | 6.500000e+01 | 7.200000e+01 | 1.000000e+02 |
| PERCENTIL_MATEMATICAS | 12527.0 | 6.397637e+01 | 2.402950e+01 | 1.000000e+00 | 4.700000e+01 | 6.700000e+01 | 8.400000e+01 | 1.000000e+02 |
| DESEMP_MATEMATICAS | 12527.0 | 3.151034e+00 | 6.811860e-01 | 1.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 | 4.000000e+00 |
| PUNT_C_NATURALES | 12527.0 | 6.280267e+01 | 1.063723e+01 | 0.000000e+00 | 5.600000e+01 | 6.400000e+01 | 7.000000e+01 | 1.000000e+02 |
| PERCENTIL_C_NATURALES | 12527.0 | 6.420212e+01 | 2.384049e+01 | 1.000000e+00 | 4.700000e+01 | 6.700000e+01 | 8.400000e+01 | 1.000000e+02 |
| DESEMP_C_NATURALES | 12527.0 | 2.971981e+00 | 7.347994e-01 | 1.000000e+00 | 3.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_SOCIALES_CIUDADANAS | 12527.0 | 6.215742e+01 | 1.125163e+01 | 2.200000e+01 | 5.500000e+01 | 6.300000e+01 | 7.000000e+01 | 1.000000e+02 |
| PERCENTIL_SOCIALES_CIUDADANAS | 12527.0 | 6.310178e+01 | 2.483422e+01 | 1.000000e+00 | 4.500000e+01 | 6.600000e+01 | 8.400000e+01 | 1.000000e+02 |
| DESEMP_SOCIALES_CIUDADANAS | 12527.0 | 2.936298e+00 | 7.899843e-01 | 1.000000e+00 | 2.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_INGLES | 12527.0 | 7.050802e+01 | 1.388719e+01 | 0.000000e+00 | 6.000000e+01 | 7.300000e+01 | 8.200000e+01 | 1.000000e+02 |
| PERCENTIL_INGLES | 12527.0 | 6.484953e+01 | 2.306537e+01 | 1.000000e+00 | 4.800000e+01 | 6.700000e+01 | 8.400000e+01 | 1.000000e+02 |
| PUNT_GLOBAL | 12527.0 | 3.190647e+02 | 4.907322e+01 | 1.370000e+02 | 2.870000e+02 | 3.260000e+02 | 3.550000e+02 | 4.750000e+02 |
| PERCENTIL_GLOBAL | 12527.0 | 6.451217e+01 | 2.340080e+01 | 1.000000e+00 | 4.800000e+01 | 6.700000e+01 | 8.400000e+01 | 1.000000e+02 |
| ESTU_INSE_INDIVIDUAL | 12268.0 | 6.585032e+01 | 8.564458e+00 | 2.159309e+01 | 5.966838e+01 | 6.641709e+01 | 7.210113e+01 | 8.358035e+01 |
| ESTU_NSE_ESTABLECIMIENTO | 12430.0 | 3.272164e+00 | 5.884799e-01 | 1.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 | 4.000000e+00 |
Un resumen de las estadísticas descriptivas de las variables cuantitativas del año 2018
-
PERIODO:
- Todos los valores son iguales a 20181, lo que indica que los datos corresponden al mismo periodo.
-
ESTU_COD_RESIDE_MCPIO, COLE_COD_MCPIO_UBICACION y ESTU_COD_MCPIO_PRESENTACION:
- El 50% de los datos están entre los códigos 11001 (Bogotá) y 76001 (Cali).
-
Puntajes y percentiles en las áreas evaluadas (PUNT_LECTURA_CRITICA, PUNT_MATEMATICAS, PUNT_C_NATURALES, PUNT_SOCIALES_CIUDADANAS, PUNT_INGLES):
- Los puntajes promedio varían entre 62 y 70 puntos, con desviaciones estándar entre 9 y 13 puntos.
- Los percentiles promedio están alrededor de 63, con desviaciones estándar cercanas a 24.
-
Desempeños en las áreas evaluadas (DESEMP_LECTURA_CRITICA, DESEMP_MATEMATICAS, DESEMP_C_NATURALES, DESEMP_SOCIALES_CIUDADANAS):
- Los desempeños promedio varían entre 2.9 y 3.4, con desviaciones estándar pequeñas (menores a 1).
-
PUNT_GLOBAL y PERCENTIL_GLOBAL:
- El puntaje global promedio es de 319 puntos, con una desviación estándar de 49 puntos.
- El percentil global promedio es de 64.5, con una desviación estándar de 23.4.
-
ESTU_INSE_INDIVIDUAL:
- El índice socioeconómico individual promedio es de 65.85, con una desviación estándar de 8.56.
- El 50% de los estudiantes tienen un índice entre 59.67 y 72.10.
-
ESTU_NSE_ESTABLECIMIENTO:
- El nivel socioeconómico promedio de los establecimientos es de 3.27, con una desviación estándar pequeña (0.59).
- La mayoría de los establecimientos se encuentran en los niveles socioeconómicos 3 y 4.
# Consultamos numeros de filas y columnas, para estar seguros.
df.shape(12527, 82)
# Consultamos si tenemos celdas con valores sin valores
null_counts = df.isnull().sum()
null_counts| 0 | |
|---|---|
| ESTU_TIPODOCUMENTO | 0 |
| ESTU_NACIONALIDAD | 0 |
| ESTU_GENERO | 0 |
| ESTU_FECHANACIMIENTO | 0 |
| PERIODO | 0 |
| ... | ... |
| ESTU_INSE_INDIVIDUAL | 259 |
| ESTU_NSE_INDIVIDUAL | 259 |
| ESTU_NSE_ESTABLECIMIENTO | 97 |
| ESTU_ESTADOINVESTIGACION | 0 |
| ESTU_PILOPAGA | 0 |
82 rows × 1 columns
# Filtramos las variables que tengan mas de un valor null con datos > 0
null_counts[null_counts > 0]| 0 | |
|---|---|
| ESTU_TIENEETNIA | 1 |
| ESTU_ETNIA | 12408 |
| FAMI_ESTRATOVIVIENDA | 464 |
| FAMI_PERSONASHOGAR | 283 |
| FAMI_CUARTOSHOGAR | 208 |
| FAMI_EDUCACIONPADRE | 433 |
| FAMI_EDUCACIONMADRE | 431 |
| FAMI_TRABAJOLABORPADRE | 254 |
| FAMI_TRABAJOLABORMADRE | 228 |
| FAMI_TIENEINTERNET | 419 |
| FAMI_TIENESERVICIOTV | 444 |
| FAMI_TIENECOMPUTADOR | 180 |
| FAMI_TIENELAVADORA | 173 |
| FAMI_TIENEHORNOMICROOGAS | 180 |
| FAMI_TIENEAUTOMOVIL | 198 |
| FAMI_TIENEMOTOCICLETA | 210 |
| FAMI_TIENECONSOLAVIDEOJUEGOS | 192 |
| FAMI_NUMLIBROS | 425 |
| FAMI_COMELECHEDERIVADOS | 441 |
| FAMI_COMECARNEPESCADOHUEVO | 454 |
| FAMI_COMECEREALFRUTOSLEGUMBRE | 451 |
| FAMI_SITUACIONECONOMICA | 199 |
| ESTU_DEDICACIONLECTURADIARIA | 436 |
| ESTU_DEDICACIONINTERNET | 458 |
| ESTU_HORASSEMANATRABAJA | 201 |
| ESTU_TIPOREMUNERACION | 254 |
| COLE_BILINGUE | 1404 |
| COLE_CARACTER | 124 |
| ESTU_INSE_INDIVIDUAL | 259 |
| ESTU_NSE_INDIVIDUAL | 259 |
| ESTU_NSE_ESTABLECIMIENTO | 97 |
Estos datos con valores en null son de estudiantes que no han respondido a esas preguntas (Por razones desconocidas), es importante tener esto en cuenta.
Ahora tratemos de ver las columnas, así en caso de volver no tenemos que ir viendo cada consulta o nos iremos perdiendo a la hora de buscar alguna variable al programar.
df.columnsIndex(['ESTU_TIPODOCUMENTO', 'ESTU_NACIONALIDAD', 'ESTU_GENERO',
'ESTU_FECHANACIMIENTO', 'PERIODO', 'ESTU_CONSECUTIVO',
'ESTU_ESTUDIANTE', 'ESTU_PAIS_RESIDE', 'ESTU_TIENEETNIA', 'ESTU_ETNIA',
'ESTU_DEPTO_RESIDE', 'ESTU_COD_RESIDE_DEPTO', 'ESTU_MCPIO_RESIDE',
'ESTU_COD_RESIDE_MCPIO', 'FAMI_ESTRATOVIVIENDA', 'FAMI_PERSONASHOGAR',
'FAMI_CUARTOSHOGAR', 'FAMI_EDUCACIONPADRE', 'FAMI_EDUCACIONMADRE',
'FAMI_TRABAJOLABORPADRE', 'FAMI_TRABAJOLABORMADRE',
'FAMI_TIENEINTERNET', 'FAMI_TIENESERVICIOTV', 'FAMI_TIENECOMPUTADOR',
'FAMI_TIENELAVADORA', 'FAMI_TIENEHORNOMICROOGAS', 'FAMI_TIENEAUTOMOVIL',
'FAMI_TIENEMOTOCICLETA', 'FAMI_TIENECONSOLAVIDEOJUEGOS',
'FAMI_NUMLIBROS', 'FAMI_COMELECHEDERIVADOS',
'FAMI_COMECARNEPESCADOHUEVO', 'FAMI_COMECEREALFRUTOSLEGUMBRE',
'FAMI_SITUACIONECONOMICA', 'ESTU_DEDICACIONLECTURADIARIA',
'ESTU_DEDICACIONINTERNET', 'ESTU_HORASSEMANATRABAJA',
'ESTU_TIPOREMUNERACION', 'COLE_CODIGO_ICFES',
'COLE_COD_DANE_ESTABLECIMIENTO', 'COLE_NOMBRE_ESTABLECIMIENTO',
'COLE_GENERO', 'COLE_NATURALEZA', 'COLE_CALENDARIO', 'COLE_BILINGUE',
'COLE_CARACTER', 'COLE_COD_DANE_SEDE', 'COLE_NOMBRE_SEDE',
'COLE_SEDE_PRINCIPAL', 'COLE_AREA_UBICACION', 'COLE_JORNADA',
'COLE_COD_MCPIO_UBICACION', 'COLE_MCPIO_UBICACION',
'COLE_COD_DEPTO_UBICACION', 'COLE_DEPTO_UBICACION',
'ESTU_PRIVADO_LIBERTAD', 'ESTU_COD_MCPIO_PRESENTACION',
'ESTU_MCPIO_PRESENTACION', 'ESTU_DEPTO_PRESENTACION',
'ESTU_COD_DEPTO_PRESENTACION', 'PUNT_LECTURA_CRITICA',
'PERCENTIL_LECTURA_CRITICA', 'DESEMP_LECTURA_CRITICA',
'PUNT_MATEMATICAS', 'PERCENTIL_MATEMATICAS', 'DESEMP_MATEMATICAS',
'PUNT_C_NATURALES', 'PERCENTIL_C_NATURALES', 'DESEMP_C_NATURALES',
'PUNT_SOCIALES_CIUDADANAS', 'PERCENTIL_SOCIALES_CIUDADANAS',
'DESEMP_SOCIALES_CIUDADANAS', 'PUNT_INGLES', 'PERCENTIL_INGLES',
'DESEMP_INGLES', 'PUNT_GLOBAL', 'PERCENTIL_GLOBAL',
'ESTU_INSE_INDIVIDUAL', 'ESTU_NSE_INDIVIDUAL',
'ESTU_NSE_ESTABLECIMIENTO', 'ESTU_ESTADOINVESTIGACION',
'ESTU_PILOPAGA'],
dtype='object')
df.dtypes| 0 | |
|---|---|
| ESTU_TIPODOCUMENTO | object |
| ESTU_NACIONALIDAD | object |
| ESTU_GENERO | object |
| ESTU_FECHANACIMIENTO | object |
| PERIODO | int64 |
| ... | ... |
| ESTU_INSE_INDIVIDUAL | float64 |
| ESTU_NSE_INDIVIDUAL | object |
| ESTU_NSE_ESTABLECIMIENTO | float64 |
| ESTU_ESTADOINVESTIGACION | object |
| ESTU_PILOPAGA | object |
82 rows × 1 columns
Variables cuantitativas
Son aquellas que representan una cantidad numérica o medida. Estas variables pueden ser discretas o continuas.
- Variables cuantitativas discretas: Son aquellas que toman valores numéricos enteros y se pueden contar, como el número de personas en una familia o en este caso el periodo en el que se encuentra el estudiante.
- Variables cuantitativas continuas: Son aquellas que pueden tomar cualquier valor dentro de un rango, y generalmente se miden en una escala continua, como la altura de una persona o el peso de un objeto.
Variables cualitativas
Son aquellas que representan cualidades o características que no se pueden medir numéricamente. Estas variables se dividen en dos subtipos:
- Variables cualitativas nominales: Son aquellas que representan categorías sin un orden intrínseco, como el color de los ojos o la marca de un automóvil.
- Variables cualitativas ordinales: Son aquellas que representan categorías con un orden natural o jerarquía, como el nivel de educación (primaria, secundaria, universitaria).
Teniendo estas definiciones importantes para nuestro analisis prosigamos a categorizar las variables que usaremos.
-
Variables cuantitativas:
-
Variables cuantitativas continuas:
- Puntajes promedio en las áreas evaluadas (PUNT_LECTURA_CRITICA, PUNT_MATEMATICAS, PUNT_C_NATURALES, PUNT_SOCIALES_CIUDADANAS, PUNT_INGLES)
- Puntaje global (PUNT_GLOBAL)
- Índice socioeconómico del evaluado (ESTU_INSE_INDIVIDUAL)
-
Variables cuantitativas discretas:
- Periodo (PERIODO)
- Código DANE del municipio de ubicación de la sede (COLE_COD_MCPIO_UBICACION)
- Código DANE del departamento de ubicación de la sede (COLE_COD_DEPTO_UBICACION)
-
-
Variables cualitativas:
-
Variables cualitativas nominales:
- Municipio de ubicación de la sede (COLE_MCPIO_UBICACION)
- Departamento de ubicación de la sede (COLE_DEPTO_UBICACION)
- Naturaleza del establecimiento (COLE_NATURALEZA)
- Jornada de la sede (COLE_JORNADA)
- Género del evaluado (ESTU_GENERO)
- Disponibilidad de computador en el hogar (FAMI_TIENECOMPUTADOR)
- Acceso a internet en el hogar (FAMI_TIENEINTERNET)
-
Variables cualitativas ordinales:
- Estrato socioeconómico de la vivienda (FAMI_ESTRATOVIVIENDA)
- Nivel educativo más alto alcanzado por el padre (FAMI_EDUCACIONPADRE)
- Nivel educativo más alto alcanzado por la madre (FAMI_EDUCACIONMADRE)
- Nivel socioeconómico del evaluado (ESTU_NSE_INDIVIDUAL)
-
Como resumen tenemos información familiar, socioeconómica, academica (Trabajos de sus padres, cosas basicas materiales, titulaciones o nivel academico en el que petenezcan como su estrato) y laboral del estudiante como información personal, y detalle de como le fue en el icfes, ademas de saber donde estudia y presento el examen. Analizamos cada variable, sacamos las importantes, las categorizamos y sabemos que son, para que sirven y nos damos una idea de que podriamos hacer con ellas.
1.3 Importacion de los datasets
Como vimos al principio importamos un solo dataset SB11_20181.TXT para
explorar sus columnas, para comprobar que todo este bien miremos el periodo.
df['PERIODO']| PERIODO | |
|---|---|
| 0 | 20181 |
| 1 | 20181 |
| 2 | 20181 |
| 3 | 20181 |
| 4 | 20181 |
| ... | ... |
| 12522 | 20181 |
| 12523 | 20181 |
| 12524 | 20181 |
| 12525 | 20181 |
| 12526 | 20181 |
12527 rows × 1 columns
De momento esta todo bien, coincide con periodo y año con el archivo, asi que
es hora de importar los demas años y guardarlos todos en una sola variable, si
mantenemos variables separadas con datasets sera mucho mas complejo por lo que
iremos trabajando y filtrando por la columna PERIODO.
import csv
import io
def read_csv_replace_null(file, encoding):
with open(file, 'r', encoding=encoding, errors='replace') as f:
content = f.read().replace('�', '') # Reemplazar bytes nulos con una cadena vacía
return pd.read_csv(io.StringIO(content), sep='¬', engine='python', quoting=csv.QUOTE_NONE, on_bad_lines='skip')# Lista de nombres de archivos
files = ['SB11_20181.TXT', 'SB11_20182.TXT', 'SB11_20191_.txt', 'SB11_20192.TXT', 'SB11_20201.txt', 'SB11_20202.txt', 'SB11_20211.txt', 'SB11_20212.txt', 'SB11_20221.TXT', 'SB11_20231.TXT', 'SB11_20232.TXT']
# Comprensión de lista para leer todos los archivos y almacenarlos en una lista
# de DataFrames en uno solo, si el archivo es SB11_20222.TXT utilizamos las correciones correspondientes.
# el 2 if, es porque SB11*20191*.txt usa | en vez de ¬ para separar los datos, ademas de ser en minusculas las columnas...
saber11 = pd.concat(
[read_csv_replace_null(path+file, 'latin-1') if file == 'SB11_20222.TXT' else
pd.read_csv(path+file, sep='|', engine='python').rename(columns=str.upper) if file == 'SB11_20191_.txt' else
pd.read_csv(path+file, sep='¬', engine='python') for file in files],
ignore_index=True
)1.4 Analizando y sanatizando datos.
Comprobemos que todo este bien, analizando cuantas columnas y alumnos tenemos (Antes habia 12mil), y si hay mas periodos, para poder trabajar.
saber11.shape(2775282, 92)
Como vemos, tenemos 2m de datos con los que podemos trabajar, y 92 columnas, por lo que hay columnas nuevas añadidas, y unos doscientos cincuenta y cinco millones trescientos veinticinco mil novecientos cuarenta y cuatro de datos.. Así que debemos ver cuales son.
saber11.columnsIndex(['ESTU_TIPODOCUMENTO', 'ESTU_NACIONALIDAD', 'ESTU_GENERO',
'ESTU_FECHANACIMIENTO', 'PERIODO', 'ESTU_CONSECUTIVO',
'ESTU_ESTUDIANTE', 'ESTU_PAIS_RESIDE', 'ESTU_TIENEETNIA', 'ESTU_ETNIA',
'ESTU_DEPTO_RESIDE', 'ESTU_COD_RESIDE_DEPTO', 'ESTU_MCPIO_RESIDE',
'ESTU_COD_RESIDE_MCPIO', 'FAMI_ESTRATOVIVIENDA', 'FAMI_PERSONASHOGAR',
'FAMI_CUARTOSHOGAR', 'FAMI_EDUCACIONPADRE', 'FAMI_EDUCACIONMADRE',
'FAMI_TRABAJOLABORPADRE', 'FAMI_TRABAJOLABORMADRE',
'FAMI_TIENEINTERNET', 'FAMI_TIENESERVICIOTV', 'FAMI_TIENECOMPUTADOR',
'FAMI_TIENELAVADORA', 'FAMI_TIENEHORNOMICROOGAS', 'FAMI_TIENEAUTOMOVIL',
'FAMI_TIENEMOTOCICLETA', 'FAMI_TIENECONSOLAVIDEOJUEGOS',
'FAMI_NUMLIBROS', 'FAMI_COMELECHEDERIVADOS',
'FAMI_COMECARNEPESCADOHUEVO', 'FAMI_COMECEREALFRUTOSLEGUMBRE',
'FAMI_SITUACIONECONOMICA', 'ESTU_DEDICACIONLECTURADIARIA',
'ESTU_DEDICACIONINTERNET', 'ESTU_HORASSEMANATRABAJA',
'ESTU_TIPOREMUNERACION', 'COLE_CODIGO_ICFES',
'COLE_COD_DANE_ESTABLECIMIENTO', 'COLE_NOMBRE_ESTABLECIMIENTO',
'COLE_GENERO', 'COLE_NATURALEZA', 'COLE_CALENDARIO', 'COLE_BILINGUE',
'COLE_CARACTER', 'COLE_COD_DANE_SEDE', 'COLE_NOMBRE_SEDE',
'COLE_SEDE_PRINCIPAL', 'COLE_AREA_UBICACION', 'COLE_JORNADA',
'COLE_COD_MCPIO_UBICACION', 'COLE_MCPIO_UBICACION',
'COLE_COD_DEPTO_UBICACION', 'COLE_DEPTO_UBICACION',
'ESTU_PRIVADO_LIBERTAD', 'ESTU_COD_MCPIO_PRESENTACION',
'ESTU_MCPIO_PRESENTACION', 'ESTU_DEPTO_PRESENTACION',
'ESTU_COD_DEPTO_PRESENTACION', 'PUNT_LECTURA_CRITICA',
'PERCENTIL_LECTURA_CRITICA', 'DESEMP_LECTURA_CRITICA',
'PUNT_MATEMATICAS', 'PERCENTIL_MATEMATICAS', 'DESEMP_MATEMATICAS',
'PUNT_C_NATURALES', 'PERCENTIL_C_NATURALES', 'DESEMP_C_NATURALES',
'PUNT_SOCIALES_CIUDADANAS', 'PERCENTIL_SOCIALES_CIUDADANAS',
'DESEMP_SOCIALES_CIUDADANAS', 'PUNT_INGLES', 'PERCENTIL_INGLES',
'DESEMP_INGLES', 'PUNT_GLOBAL', 'PERCENTIL_GLOBAL',
'ESTU_INSE_INDIVIDUAL', 'ESTU_NSE_INDIVIDUAL',
'ESTU_NSE_ESTABLECIMIENTO', 'ESTU_ESTADOINVESTIGACION', 'ESTU_PILOPAGA',
'ESTU_LIMITA_MOTRIZ', 'ESTU_GENERACION-E', 'ESTU_GENERACIONE',
'PERCENTIL_ESPECIAL_GLOBAL', 'ESTU_AGREGADO', 'ESTU_PRESENTACIONSABADO',
'SEED_CODIGOMEN', 'SEED_NOMBRE', 'ESTU_LENGUANATIVA',
'ESTU_GENERACION'],
dtype='object')
Estas serias las nuevas columnas
ESTU_GENERACION-EESTU_GENERACIONEPERCENTIL_ESPECIAL_GLOBALESTU_AGREGADOESTU_PRESENTACIONSABADOSEED_CODIGOMENSEED_NOMBREESTU_LENGUANATIVAESTU_GENERACION
Las iremos ignorando en este analisis ya que no aportan tanto, ademas debemos tener encuenta los resultados en cada año no podemos ir añadiendo columnas nuevas, sin saber que en los anteriores años estas preguntas no estan respondidas por lo que habran muchas respuestas en NULL (sin respuesta).
# Consultamos si tenemos celdas con valores sin valores
null_counts = saber11.isnull().sum()
null_counts[null_counts > 0]| 0 | |
|---|---|
| ESTU_GENERO | 219 |
| ESTU_TIENEETNIA | 570590 |
| ESTU_ETNIA | 2700179 |
| ESTU_DEPTO_RESIDE | 1383 |
| ESTU_COD_RESIDE_DEPTO | 1383 |
| ESTU_MCPIO_RESIDE | 1383 |
| ESTU_COD_RESIDE_MCPIO | 1383 |
| FAMI_ESTRATOVIVIENDA | 175075 |
| FAMI_PERSONASHOGAR | 98623 |
| FAMI_CUARTOSHOGAR | 103634 |
| FAMI_EDUCACIONPADRE | 153482 |
| FAMI_EDUCACIONMADRE | 153885 |
| FAMI_TRABAJOLABORPADRE | 111377 |
| FAMI_TRABAJOLABORMADRE | 106420 |
| FAMI_TIENEINTERNET | 156095 |
| FAMI_TIENESERVICIOTV | 162269 |
| FAMI_TIENECOMPUTADOR | 107012 |
| FAMI_TIENELAVADORA | 102971 |
| FAMI_TIENEHORNOMICROOGAS | 106871 |
| FAMI_TIENEAUTOMOVIL | 109584 |
| FAMI_TIENEMOTOCICLETA | 105170 |
| FAMI_TIENECONSOLAVIDEOJUEGOS | 109449 |
| FAMI_NUMLIBROS | 206262 |
| FAMI_COMELECHEDERIVADOS | 179782 |
| FAMI_COMECARNEPESCADOHUEVO | 163752 |
| FAMI_COMECEREALFRUTOSLEGUMBRE | 175246 |
| FAMI_SITUACIONECONOMICA | 108257 |
| ESTU_DEDICACIONLECTURADIARIA | 159984 |
| ESTU_DEDICACIONINTERNET | 165055 |
| ESTU_HORASSEMANATRABAJA | 104407 |
| ESTU_TIPOREMUNERACION | 109694 |
| COLE_BILINGUE | 461550 |
| COLE_CARACTER | 85283 |
| ESTU_COD_MCPIO_PRESENTACION | 208 |
| ESTU_MCPIO_PRESENTACION | 208 |
| ESTU_DEPTO_PRESENTACION | 208 |
| ESTU_COD_DEPTO_PRESENTACION | 208 |
| PUNT_INGLES | 6843 |
| PERCENTIL_INGLES | 6433 |
| DESEMP_INGLES | 6433 |
| PERCENTIL_GLOBAL | 6488 |
| ESTU_INSE_INDIVIDUAL | 113465 |
| ESTU_NSE_INDIVIDUAL | 113465 |
| ESTU_NSE_ESTABLECIMIENTO | 16435 |
| ESTU_PILOPAGA | 2762755 |
| ESTU_LIMITA_MOTRIZ | 2775281 |
| ESTU_GENERACION-E | 625850 |
| ESTU_GENERACIONE | 2754199 |
| PERCENTIL_ESPECIAL_GLOBAL | 2716195 |
| ESTU_AGREGADO | 2762423 |
| ESTU_PRESENTACIONSABADO | 2211850 |
| SEED_CODIGOMEN | 2762578 |
| SEED_NOMBRE | 2762578 |
| ESTU_LENGUANATIVA | 2765972 |
| ESTU_GENERACION | 2224133 |
saber11.describe().transpose()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| PERIODO | 2775282.0 | 2.020557e+04 | 1.788081e+01 | 2.018100e+04 | 2.019400e+04 | 2.020400e+04 | 2.021400e+04 | 2.023400e+04 |
| ESTU_COD_RESIDE_DEPTO | 2773899.0 | 4.028716e+01 | 8.555583e+02 | 5.000000e+00 | 1.100000e+01 | 2.300000e+01 | 5.400000e+01 | 9.999900e+04 |
| ESTU_COD_RESIDE_MCPIO | 2773899.0 | 3.321133e+04 | 2.664617e+04 | 5.001000e+03 | 1.100100e+04 | 2.300100e+04 | 5.424500e+04 | 9.999900e+04 |
| COLE_CODIGO_ICFES | 2775282.0 | 2.500845e+05 | 2.706402e+05 | 1.800000e+01 | 5.244900e+04 | 1.262010e+05 | 4.317340e+05 | 8.152660e+05 |
| COLE_COD_DANE_ESTABLECIMIENTO | 2775282.0 | 2.073891e+11 | 9.406685e+10 | 1.050010e+11 | 1.180010e+11 | 1.760010e+11 | 3.080010e+11 | 8.548740e+11 |
| COLE_COD_DANE_SEDE | 2775282.0 | 2.078808e+11 | 9.462532e+10 | 1.050010e+11 | 1.187530e+11 | 1.760010e+11 | 3.080010e+11 | 8.548740e+11 |
| COLE_COD_MCPIO_UBICACION | 2775282.0 | 3.322695e+04 | 2.661775e+04 | 5.001000e+03 | 1.100100e+04 | 2.300100e+04 | 5.423900e+04 | 9.977300e+04 |
| COLE_COD_DEPTO_UBICACION | 2775282.0 | 3.299041e+01 | 2.659654e+01 | 5.000000e+00 | 1.100000e+01 | 2.300000e+01 | 5.400000e+01 | 9.900000e+01 |
| ESTU_COD_MCPIO_PRESENTACION | 2775074.0 | 3.319458e+04 | 2.668342e+04 | 5.001000e+03 | 1.100100e+04 | 2.300100e+04 | 5.417200e+04 | 9.977300e+04 |
| ESTU_COD_DEPTO_PRESENTACION | 2775074.0 | 3.297709e+01 | 2.666027e+01 | 5.000000e+00 | 1.100000e+01 | 2.300000e+01 | 5.400000e+01 | 9.900000e+01 |
| PUNT_LECTURA_CRITICA | 2775282.0 | 5.272982e+01 | 1.053381e+01 | 0.000000e+00 | 4.500000e+01 | 5.300000e+01 | 6.000000e+01 | 1.000000e+02 |
| PERCENTIL_LECTURA_CRITICA | 2775282.0 | 5.006827e+01 | 2.896852e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| DESEMP_LECTURA_CRITICA | 2775282.0 | 2.649610e+00 | 7.512747e-01 | 1.000000e+00 | 2.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_MATEMATICAS | 2775282.0 | 5.085867e+01 | 1.214063e+01 | 0.000000e+00 | 4.200000e+01 | 5.100000e+01 | 5.900000e+01 | 1.000000e+02 |
| PERCENTIL_MATEMATICAS | 2775282.0 | 5.010526e+01 | 2.895552e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| DESEMP_MATEMATICAS | 2775282.0 | 2.455762e+00 | 7.551350e-01 | 1.000000e+00 | 2.000000e+00 | 3.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_C_NATURALES | 2775282.0 | 4.907280e+01 | 1.066725e+01 | 0.000000e+00 | 4.100000e+01 | 4.800000e+01 | 5.700000e+01 | 1.000000e+02 |
| PERCENTIL_C_NATURALES | 2775282.0 | 5.014289e+01 | 2.893142e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| DESEMP_C_NATURALES | 2775282.0 | 2.070502e+00 | 7.646729e-01 | 1.000000e+00 | 2.000000e+00 | 2.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_SOCIALES_CIUDADANAS | 2775282.0 | 4.787349e+01 | 1.216655e+01 | 0.000000e+00 | 3.800000e+01 | 4.700000e+01 | 5.700000e+01 | 1.000000e+02 |
| PERCENTIL_SOCIALES_CIUDADANAS | 2775282.0 | 5.014310e+01 | 2.892459e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| DESEMP_SOCIALES_CIUDADANAS | 2775282.0 | 2.001436e+00 | 8.346854e-01 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PUNT_INGLES | 2768439.0 | 4.977864e+01 | 1.283478e+01 | 0.000000e+00 | 4.000000e+01 | 4.800000e+01 | 5.700000e+01 | 1.000000e+02 |
| PERCENTIL_INGLES | 2768849.0 | 5.016052e+01 | 2.890562e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| PUNT_GLOBAL | 2775282.0 | 2.505214e+02 | 5.165701e+01 | 0.000000e+00 | 2.110000e+02 | 2.470000e+02 | 2.870000e+02 | 5.000000e+02 |
| PERCENTIL_GLOBAL | 2768794.0 | 5.002996e+01 | 2.896563e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| ESTU_INSE_INDIVIDUAL | 2661817.0 | 5.057651e+01 | 9.703502e+00 | 1.134724e+01 | 4.385332e+01 | 5.025759e+01 | 5.669878e+01 | 8.483637e+01 |
| ESTU_NSE_ESTABLECIMIENTO | 2758847.0 | 2.405172e+00 | 6.729321e-01 | 1.000000e+00 | 2.000000e+00 | 2.000000e+00 | 3.000000e+00 | 4.000000e+00 |
| PERCENTIL_ESPECIAL_GLOBAL | 59087.0 | 5.041936e+01 | 2.888397e+01 | 1.000000e+00 | 2.500000e+01 | 5.000000e+01 | 7.500000e+01 | 1.000000e+02 |
| SEED_CODIGOMEN | 12704.0 | 1.443476e+02 | 6.276720e+01 | 5.000000e+00 | 6.800000e+01 | 1.880000e+02 | 1.880000e+02 | 2.720000e+02 |
Saber los años y periodos de las pruebas saber11 que iremos trabajando.
saber11['PERIODO'].unique()array([20181, 20182, 20191, 20194, 20201, 20204, 20211, 20214, 20221,
20231, 20234])
Ya hemos identificado varios errores, y los hemos arreglado, ademas de que tenemos la
columna PERIODO funcional, que era nuestro objetivo. Nuestro otro objetivo es saber
que nuestra variable segunda mas importante (COLE_COD_DANE_SEDE) funcione bien,
ya que con esta sabremos la ubicacion exacta de cada colegio.
saber11['COLE_COD_DANE_SEDE']| COLE_COD_DANE_SEDE | |
|---|---|
| 0 | 319001002330 |
| 1 | 319001002330 |
| 2 | 319001002330 |
| 3 | 319001002330 |
| 4 | 319001002330 |
| ... | ... |
| 2775277 | 117444000818 |
| 2775278 | 117444000818 |
| 2775279 | 173283000038 |
| 2775280 | 173283000038 |
| 2775281 | 223807002839 |
2775282 rows × 1 columns
saber11['COLE_COD_DANE_SEDE'] = saber11['COLE_COD_DANE_SEDE'].fillna(0).astype(int)Con algunos ajustes hicimos que el codigo DANE de cada sede este bien formateado, ya que como vimos mas arriba era de tipo float64, es decir, decimal. Nosotros buscamos que nuestro codigo sea un entero. (Tenemos que cuidar nuestras variables como cientificos, ya que seran el resultado de nuestra investigacion).
Investigando un poco y mirando el funcionamiento del codigo interno de la web geoportal.dane.gov.co, podemos identificar con el codigo informacion tal como nombre, longitud, direccion, latitud, nombre, etc. Luego haremos una pequeña funcion para poder operar con esta web del gobierno.
# Comprobamos que nuestra variable categorica este bien
# aparte que nos damos una idea de que jornadas existen.
saber11['COLE_JORNADA'].unique()array(['MAÑANA', 'COMPLETA', 'TARDE', 'NOCHE', 'UNICA', 'SABATINA'], dtype=object)
# Saber si el estudiante como su familia tienen internet. (Binaria)
saber11['FAMI_TIENEINTERNET'].unique()array(['Si', 'No', nan], dtype=object)
# Lo mismo si tienen algun computador con el que trabajar. (Binaria)
saber11['FAMI_TIENECOMPUTADOR'].unique()array(['Si', 'No', nan], dtype=object)
# Estrato del 0 al 6, donde 0 no tiene estrato. Luego las volveremos numericas.
saber11['FAMI_ESTRATOVIVIENDA'].unique()array(['Estrato 3', 'Estrato 4', 'Estrato 1', 'Estrato 2', 'Estrato 5',
'Estrato 6', nan, 'Sin Estrato'], dtype=object)
# Educacion del padre, probablemente lo manejemos como binaria.
saber11['FAMI_EDUCACIONPADRE'].unique()array(['Secundaria (Bachillerato) completa',
'Educación profesional completa', 'Primaria completa',
'Técnica o tecnológica completa', 'Postgrado',
'Secundaria (Bachillerato) incompleta', nan, 'No sabe',
'Educación profesional incompleta', 'Primaria incompleta',
'Ninguno', 'Técnica o tecnológica incompleta', 'No Aplica'],
dtype=object)
2. FASE EXPLORACIÓN (VISUAL)
Para esta fase usaremos matploit para graficar, y seabor para simplificar la creación de gráficos complejos al proporcionar funciones de alto nivel para gráficos como diagramas de dispersión con líneas de regresión, matrices de correlación, gráficos de distribución conjunta, diagramas de violín y mucho más.
import matplotlib.pyplot as plt
import seaborn as snsPor ejemplo, si queremos ver histogramas de cada variable. Luego iremos combinandolas para sacar las conclusiones objetivo que tenemos.
saber11.hist(figsize=(30,35))
plt.show()
Es hora de combinar variables para nuestros histogramas y sacar conclusiones. Pero antes, busquemos nuestro colegio preferido.
instuto = saber11[saber11['COLE_NOMBRE_ESTABLECIMIENTO'].str.contains('COLEGIO INSTITUTO TECNICO INTERNACIONAL', case=False)]['COLE_NOMBRE_ESTABLECIMIENTO']
instuto| COLE_NOMBRE_ESTABLECIMIENTO | |
|---|---|
| 28813 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 30925 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 31056 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 40353 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 42675 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| ... | ... |
| 2734602 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 2739100 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 2758677 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 2760805 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
| 2762246 | COLEGIO INSTITUTO TECNICO INTERNACIONAL (IED) |
794 rows × 1 columns
import numpy as np
# Obtener los datos únicos de 'PERIODO' y 'PUNT_MATEMATICAS'
periodos = saber11['PERIODO'].unique()
puntajes = saber11['PUNT_MATEMATICAS']
# Ordenar los períodos de forma cronológica y alinear con los puntajes correspondientes
periodos_ordenados, puntajes_ordenados = zip(*sorted(zip(periodos, puntajes)))
# Crear el gráfico
fig, ax = plt.subplots(figsize=(10, 6))
bar_width = 0.6
bar_positions = np.arange(len(periodos_ordenados))
# Barras
bars = ax.bar(bar_positions, puntajes_ordenados, bar_width, color='skyblue', edgecolor='black')
# Línea de tendencia
z = np.polyfit(bar_positions, puntajes_ordenados, 1)
p = np.poly1d(z)
ax.plot(bar_positions, p(bar_positions), 'r--', linewidth=2, label='Tendencia')
# Etiquetas y título
ax.set_xlabel('Período', fontsize=12)
ax.set_ylabel('Puntaje en Matemáticas', fontsize=12)
ax.set_title('Puntaje en Matemáticas por Período', fontsize=14, fontweight='bold')
ax.set_xticks(bar_positions)
ax.set_xticklabels(periodos_ordenados, rotation=45, ha='right')
# Anotaciones
covid_start = 20201 # Período de inicio del COVID-19
covid_end = 20211 # Período de cierre del COVID-19
ax.annotate('Inicio del COVID-19', xy=(periodos_ordenados.index(covid_start), puntajes_ordenados[periodos_ordenados.index(covid_start)]),
xytext=(0.2, 0.9), textcoords='axes fraction', fontsize=10,
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='left', verticalalignment='top')
ax.annotate('Cierre del COVID-19', xy=(periodos_ordenados.index(covid_end), puntajes_ordenados[periodos_ordenados.index(covid_end)]),
xytext=(0.8, 0.9), textcoords='axes fraction', fontsize=10,
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='right', verticalalignment='top')
# Leyenda
ax.legend(fontsize=10)
# Ajustar márgenes y espaciado
plt.tight_layout()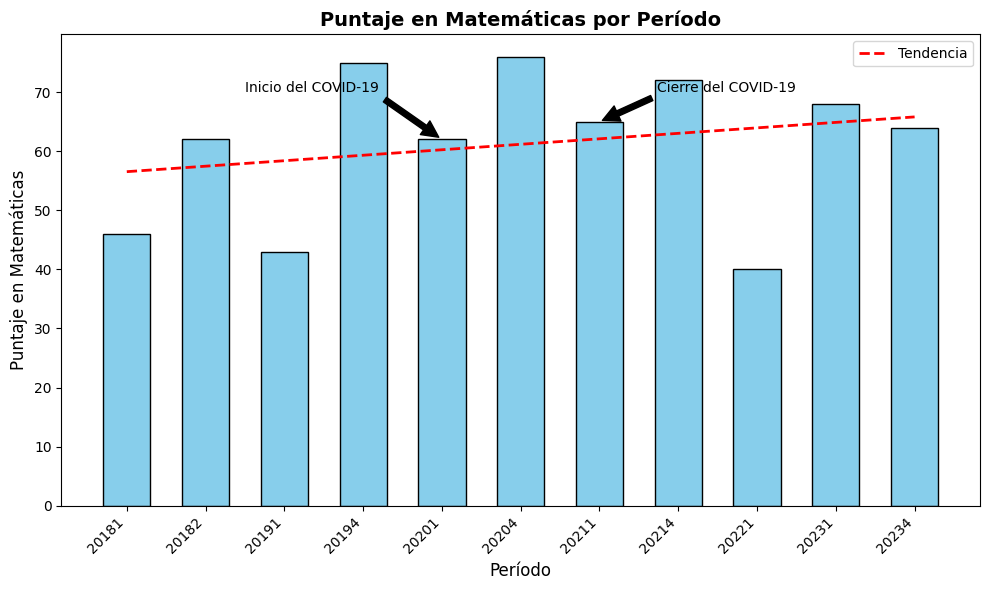
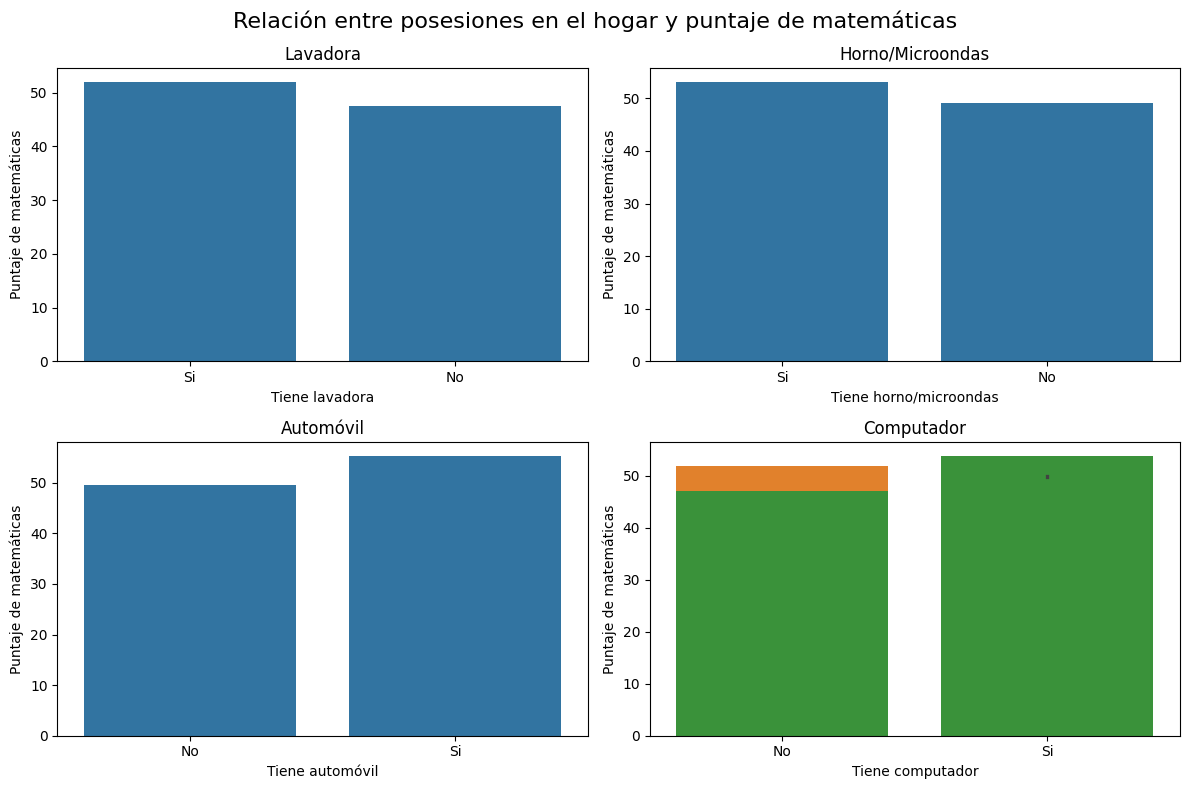
Puntaje de Matematicas en Promedio por Disponibilidad de Computador en el Hogar
# Calculamos el puntaje promedio por disponibilidad de computador en el hogar
puntajes_promedio = saber11.groupby('FAMI_TIENECOMPUTADOR')['PUNT_MATEMATICAS'].mean()
ax = puntajes_promedio.plot(kind='bar', figsize=(6, 6), color='skyblue', edgecolor='black', linewidth=1.5)
# Configuramos etiquetas y título
ax.set_xlabel('Disponibilidad de Computador en el Hogar', fontsize=12)
ax.set_ylabel('Puntaje Global Promedio', fontsize=12)
ax.set_title('Puntaje de Matematicas en Promedio por Disponibilidad de Computador en el Hogar', fontsize=14, fontweight='bold')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()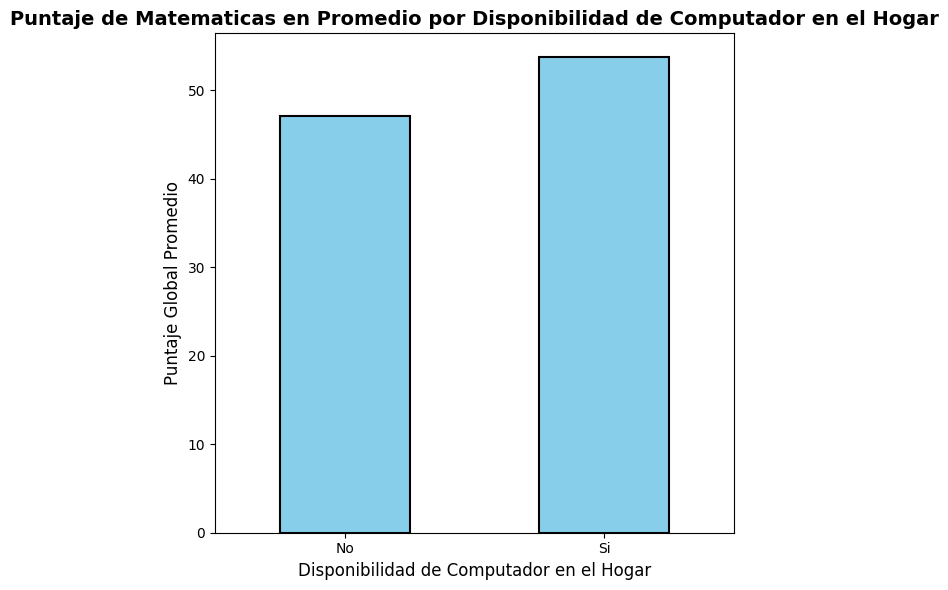
Calcular el puntaje promedio de matemáticas por acceso a internet en el hogar
# Calculamos el puntaje promedio de matemáticas por acceso a internet en el hogar
puntajes_promedio = saber11.groupby('FAMI_TIENEINTERNET')['PUNT_MATEMATICAS'].mean()
# Creamos el gráfico de barras
ax = puntajes_promedio.plot(kind='bar', figsize=(6, 6), color='skyblue', edgecolor='black', linewidth=1.5)
# Configuramos etiquetas y título
ax.set_xlabel('Acceso a Internet en el Hogar', fontsize=12)
ax.set_ylabel('Puntaje Promedio de Matemáticas', fontsize=12)
ax.set_title('Puntaje Promedio de Matemáticas por Acceso a Internet en el Hogar', fontsize=14, fontweight='bold')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()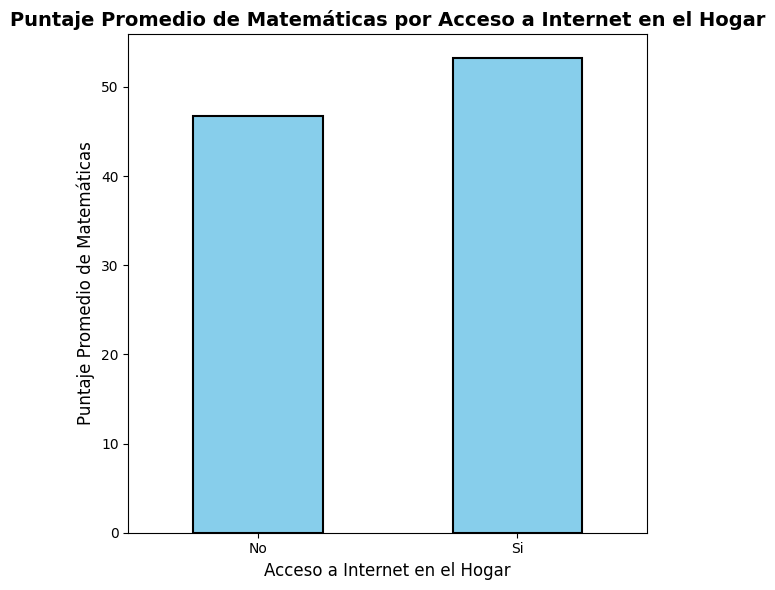
Calcular el puntaje promedio de matemáticas por nivel socioeconómico del establecimiento
# Calculamos el puntaje promedio de matemáticas por nivel socioeconómico del establecimiento
puntajes_promedio = saber11.groupby('ESTU_NSE_ESTABLECIMIENTO')['PUNT_MATEMATICAS'].mean()
# Crear el gráfico de barras
ax = puntajes_promedio.plot(kind='bar', figsize=(8, 6), color='skyblue', edgecolor='black', linewidth=1.5)
# Configurar etiquetas y título
ax.set_xlabel('Nivel Socioeconómico del Establecimiento', fontsize=12)
ax.set_ylabel('Puntaje Promedio de Matemáticas', fontsize=12)
ax.set_title('Puntaje Promedio de Matemáticas por Nivel Socioeconómico del Establecimiento', fontsize=14, fontweight='bold')
# Ajustamos la rotación de las etiquetas del eje x
plt.xticks(rotation=0)
# Ajustar márgenes y espaciado
plt.tight_layout()
plt.show()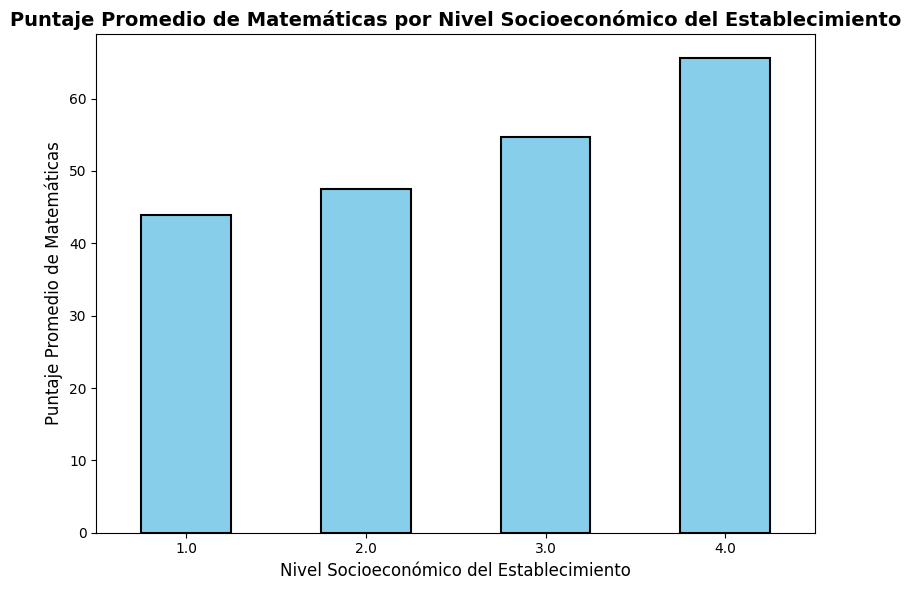
Calcular el puntaje promedio de matemáticas por jornada académica
# Calculamos el puntaje promedio de matemáticas por jornada académica
puntajes_promedio = saber11.groupby('COLE_JORNADA')['PUNT_MATEMATICAS'].mean()
# Creamos el gráfico de barras
ax = puntajes_promedio.plot(kind='bar', figsize=(8, 6), color='skyblue', edgecolor='black', linewidth=1.5)
# Configuramos etiquetas y título
ax.set_xlabel('Jornada Académica', fontsize=12)
ax.set_ylabel('Puntaje Promedio de Matemáticas', fontsize=12)
ax.set_title('Puntaje Promedio de Matemáticas por Jornada Académica', fontsize=14, fontweight='bold')
# Ajustamos la rotación de las etiquetas del eje x
plt.xticks(rotation=0)
# Ajustamos márgenes y espaciado
plt.tight_layout()
plt.show()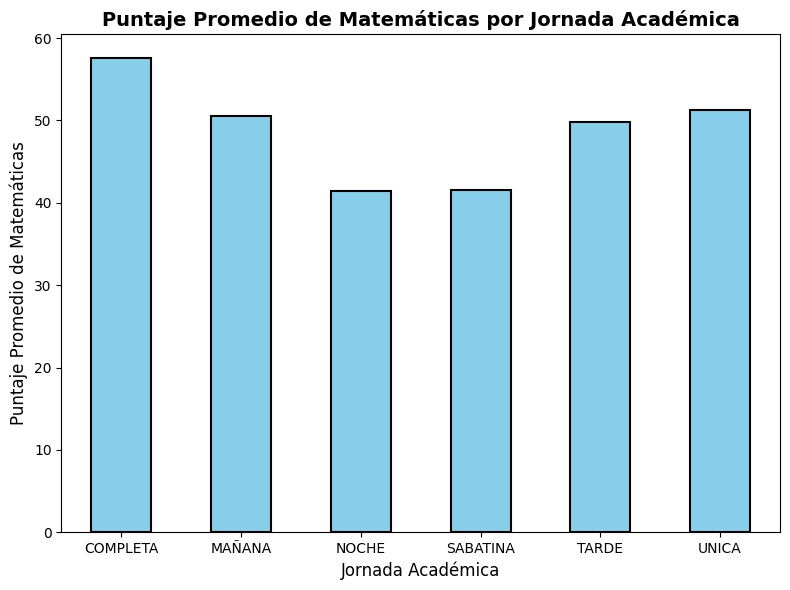
Puntaje Promedio de Matemáticas de los estudiantes por Nivel Educativo de los Padres
# Calculamos el puntaje promedio de matemáticas por nivel educativo del padre
puntajes_promedio_padre = saber11.groupby('FAMI_EDUCACIONPADRE')['PUNT_MATEMATICAS'].mean()
# Calculamos el puntaje promedio de matemáticas por nivel educativo de la madre
puntajes_promedio_madre = saber11.groupby('FAMI_EDUCACIONMADRE')['PUNT_MATEMATICAS'].mean()
# Creamos el gráfico de barras para el nivel educativo del padre
ax1 = puntajes_promedio_padre.plot(kind='bar', figsize=(10, 6), color='skyblue', edgecolor='black', linewidth=1.5, position=1, width=0.4)
# Creamos el gráfico de barras para el nivel educativo de la madre
ax2 = puntajes_promedio_madre.plot(kind='bar', figsize=(10, 6), color='lightgreen', edgecolor='black', linewidth=1.5, position=0, width=0.4)
# Configuramos etiquetas y título
ax1.set_xlabel('Nivel Educativo de los Padres', fontsize=12)
ax1.set_ylabel('Puntaje Promedio de Matemáticas', fontsize=12)
ax1.set_title('Puntaje Promedio de Matemáticas de los estudiantes por Nivel Educativo de los Padres', fontsize=14, fontweight='bold')
# Crear la leyenda
ax1.legend(['Padre', 'Madre'], loc='upper right')
# Ajustar la rotación de las etiquetas del eje x
plt.xticks(rotation=45, ha='right')
# Ajustar márgenes y espaciado
plt.tight_layout()
plt.show()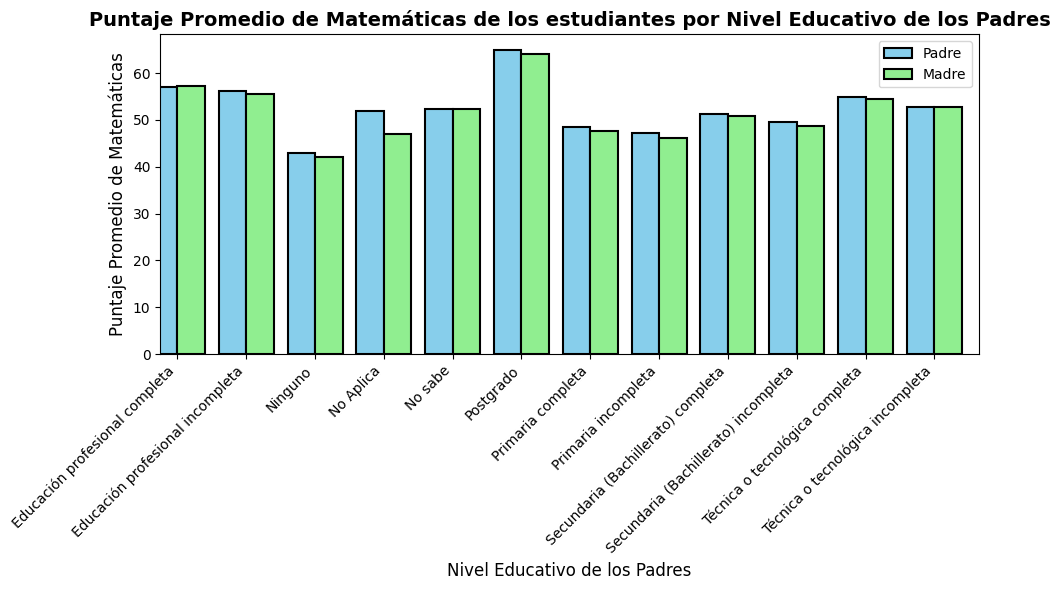
Relación entre INSE y Puntaje de Matemáticas
# Crear el gráfico de dispersión
plt.figure(figsize=(8, 6))
plt.scatter(saber11['ESTU_INSE_INDIVIDUAL'], saber11['PUNT_MATEMATICAS'], alpha=0.5)
# Configurar etiquetas y título
plt.xlabel('Índice Socioeconómico Individual (INSE)', fontsize=12)
plt.ylabel('Puntaje de Matemáticas', fontsize=12)
plt.title('Relación entre INSE y Puntaje de Matemáticas', fontsize=14, fontweight='bold')
# Ajustar márgenes y espaciado
plt.tight_layout()
plt.show()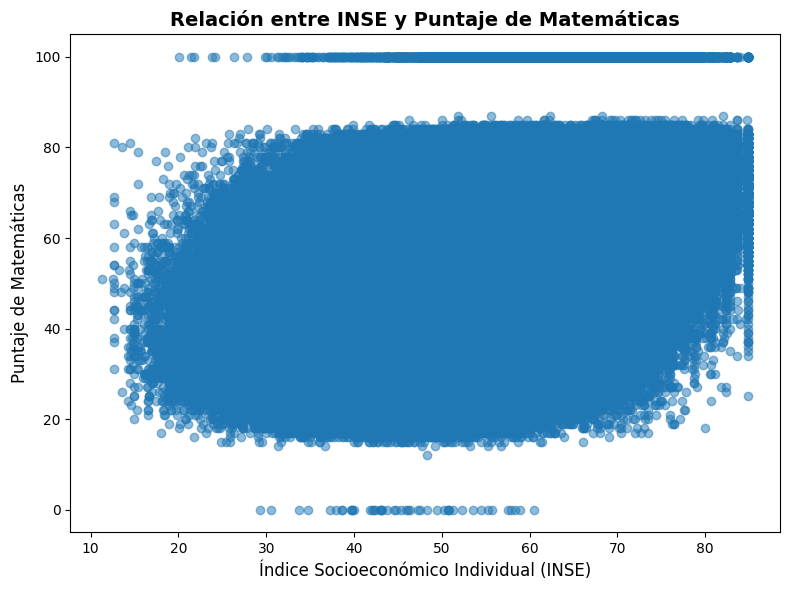
-
A medida que aumenta el INSE, la dispersión de los puntos se reduce gradualmente. Esto indica que, en general, los estudiantes de estratos socioeconómicos más altos tienden a tener puntajes de matemáticas más consistentes y agrupados en un rango más estrecho.
-
La dispersión de los puntos es mayor en los niveles más bajos del INSE (por debajo de 40). Esto sugiere que entre los estudiantes de estratos socioeconómicos más bajos, hay una mayor variabilidad en los puntajes de matemáticas. Algunos estudiantes de estos estratos obtienen puntajes relativamente altos, mientras que otros obtienen puntajes bajos.
-
Hay algunos valores atípicos en el gráfico, especialmente en los niveles más altos del INSE (por encima de 80). Estos puntos representan estudiantes con puntajes de matemáticas excepcionalmente altos en relación con su INSE. Sería interesante investigar las características y circunstancias específicas de estos estudiantes.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler, MaxAbsScaler# Seleccionar las variables de interés
variables = [
"PERIODO",
"PUNT_MATEMATICAS",
"ESTU_GENERO",
"FAMI_TIENECOMPUTADOR",
"FAMI_TIENEINTERNET",
"FAMI_ESTRATOVIVIENDA",
"COLE_COD_DANE_SEDE",
"COLE_COD_MCPIO_UBICACION",
"COLE_NATURALEZA",
'FAMI_EDUCACIONPADRE',
'FAMI_EDUCACIONMADRE',
'COLE_JORNADA',
'COLE_BILINGUE',
'COLE_CARACTER',
'FAMI_PERSONASHOGAR',
'FAMI_CUARTOSHOGAR',
'ESTU_DEDICACIONLECTURADIARIA',
'ESTU_DEDICACIONINTERNET',
'FAMI_TRABAJOLABORPADRE',
'FAMI_TRABAJOLABORMADRE',
'FAMI_TIENELAVADORA',
'FAMI_TIENEHORNOMICROOGAS',
'FAMI_TIENEAUTOMOVIL',
'FAMI_TIENEMOTOCICLETA',
'FAMI_TIENECONSOLAVIDEOJUEGOS',
'FAMI_COMELECHEDERIVADOS',
'FAMI_COMECARNEPESCADOHUEVO',
'FAMI_COMECEREALFRUTOSLEGUMBRE',
'ESTU_HORASSEMANATRABAJA',
"COLE_JORNADA"
]# Normalizamos y usamos solo las variables objetivos que tenemos como interes.
saber11_n = saber11[variables]
saber11_n| PERIODO | PUNT_MATEMATICAS | ESTU_GENERO | FAMI_TIENECOMPUTADOR | FAMI_TIENEINTERNET | FAMI_ESTRATOVIVIENDA | COLE_COD_DANE_SEDE | COLE_COD_MCPIO_UBICACION | COLE_NATURALEZA | FAMI_EDUCACIONPADRE | ... | FAMI_TIENELAVADORA | FAMI_TIENEHORNOMICROOGAS | FAMI_TIENEAUTOMOVIL | FAMI_TIENEMOTOCICLETA | FAMI_TIENECONSOLAVIDEOJUEGOS | FAMI_COMELECHEDERIVADOS | FAMI_COMECARNEPESCADOHUEVO | FAMI_COMECEREALFRUTOSLEGUMBRE | ESTU_HORASSEMANATRABAJA | COLE_JORNADA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20181 | 46 | F | Si | Si | Estrato 3 | 319001002330 | 19001 | NO OFICIAL | Secundaria (Bachillerato) completa | ... | Si | Si | No | No | No | Todos o casi todos los días | Todos o casi todos los días | 3 a 5 veces por semana | 0 | MAÑANA |
| 1 | 20181 | 62 | M | Si | Si | Estrato 4 | 319001002330 | 19001 | NO OFICIAL | Educación profesional completa | ... | Si | Si | Si | Si | Si | Todos o casi todos los días | Todos o casi todos los días | 1 o 2 veces por semana | 0 | MAÑANA |
| 2 | 20181 | 43 | F | No | No | Estrato 1 | 319001002330 | 19001 | NO OFICIAL | Secundaria (Bachillerato) completa | ... | No | No | No | No | No | Todos o casi todos los días | Nunca o rara vez comemos eso | Todos o casi todos los días | 0 | MAÑANA |
| 3 | 20181 | 75 | M | Si | No | Estrato 1 | 319001002330 | 19001 | NO OFICIAL | Primaria completa | ... | No | Si | Si | No | Si | Todos o casi todos los días | Todos o casi todos los días | Nunca o rara vez comemos eso | 0 | MAÑANA |
| 4 | 20181 | 62 | F | Si | Si | Estrato 2 | 319001002330 | 19001 | NO OFICIAL | Técnica o tecnológica completa | ... | No | No | No | No | No | Todos o casi todos los días | 3 a 5 veces por semana | 1 o 2 veces por semana | 0 | MAÑANA |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2775277 | 20234 | 38 | F | No | Si | Estrato 2 | 117444000818 | 17444 | OFICIAL | Primaria completa | ... | No | No | No | No | No | 1 o 2 veces por semana | Todos o casi todos los días | 1 o 2 veces por semana | 0 | UNICA |
| 2775278 | 20234 | 48 | F | No | Si | Estrato 1 | 117444000818 | 17444 | OFICIAL | Secundaria (Bachillerato) completa | ... | Si | No | No | Si | No | 3 a 5 veces por semana | Nunca o rara vez comemos eso | Todos o casi todos los días | 0 | UNICA |
| 2775279 | 20234 | 61 | F | No | No | Estrato 1 | 173283000038 | 73283 | OFICIAL | Primaria completa | ... | Si | No | No | No | No | 1 o 2 veces por semana | 3 a 5 veces por semana | Nunca o rara vez comemos eso | 0 | UNICA |
| 2775280 | 20234 | 73 | F | Si | Si | Estrato 3 | 173283000038 | 73283 | OFICIAL | Educación profesional completa | ... | Si | Si | Si | No | No | 3 a 5 veces por semana | Todos o casi todos los días | 3 a 5 veces por semana | 0 | UNICA |
| 2775281 | 20234 | 43 | F | No | No | Estrato 1 | 223807002839 | 23807 | OFICIAL | Secundaria (Bachillerato) completa | ... | Si | No | No | Si | No | 1 o 2 veces por semana | 1 o 2 veces por semana | 3 a 5 veces por semana | 0 | UNICA |
2775282 rows × 30 columns
saber11_n['PERIODO'].unique()array([20181, 20182, 20191, 20194, 20201, 20204, 20211, 20214, 20221,
20231, 20234])
# Filtrar los datos por colegios públicos de Bogotá
saber11_n = saber11_n[(saber11_n['COLE_COD_MCPIO_UBICACION'] == 11001)]saber11_n['PERIODO'].unique()array([20181, 20182, 20191, 20194, 20201, 20204, 20211, 20214, 20221,
20231, 20234])
# Convertir variables categóricas a variables dummy
saber11_n = pd.get_dummies(
data=saber11_n,
prefix="OHE",
prefix_sep="_",
columns=[
"ESTU_GENERO",
"FAMI_ESTRATOVIVIENDA",
"COLE_NATURALEZA",
'FAMI_EDUCACIONPADRE',
'FAMI_EDUCACIONMADRE',
'COLE_JORNADA',
'COLE_BILINGUE',
'COLE_CARACTER',
'FAMI_PERSONASHOGAR',
'FAMI_CUARTOSHOGAR',
'ESTU_DEDICACIONLECTURADIARIA',
'ESTU_DEDICACIONINTERNET',
'FAMI_TRABAJOLABORPADRE',
'FAMI_TRABAJOLABORMADRE',
'FAMI_TIENELAVADORA',
'FAMI_TIENEHORNOMICROOGAS',
'FAMI_TIENEAUTOMOVIL',
'FAMI_TIENEMOTOCICLETA',
'FAMI_TIENECONSOLAVIDEOJUEGOS',
'FAMI_COMELECHEDERIVADOS',
'FAMI_COMECARNEPESCADOHUEVO',
'FAMI_COMECEREALFRUTOSLEGUMBRE',
'ESTU_HORASSEMANATRABAJA',
],
drop_first=True,
dtype="int8",
)
saber11*n = pd.get_dummies(
data=saber11_n,
prefix=["FAMI_TIENECOMPUTADOR", "FAMI_TIENEINTERNET"], # Especificar prefijos diferentes para cada variable
prefix_sep="*",
columns=["FAMI_TIENECOMPUTADOR", "FAMI_TIENEINTERNET"], # Especificar las columnas a codificar
drop_first=True,
dtype="int8",
)
saber11_n| PERIODO | PUNT_MATEMATICAS | COLE_COD_DANE_SEDE | COLE_COD_MCPIO_UBICACION | OHE_M | OHE_Estrato 2 | OHE_Estrato 3 | OHE_Estrato 4 | OHE_Estrato 5 | OHE_Estrato 6 | ... | OHE_Todos o casi todos los días | OHE_3 a 5 veces por semana | OHE_Nunca o rara vez comemos eso | OHE_Todos o casi todos los días | OHE_Entre 11 y 20 horas | OHE_Entre 21 y 30 horas | OHE_Menos de 10 horas | OHE_Más de 30 horas | FAMI_TIENECOMPUTADOR_Si | FAMI_TIENEINTERNET_Si | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 266 | 20181 | 74 | 311001042667 | 11001 | 1 | 0 | 0 | 0 | 0 | 1 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 267 | 20181 | 78 | 311001042667 | 11001 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 268 | 20181 | 78 | 311001042667 | 11001 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 269 | 20181 | 60 | 311001042667 | 11001 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 270 | 20181 | 63 | 311001042667 | 11001 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2775242 | 20234 | 44 | 311001005451 | 11001 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 2775259 | 20234 | 25 | 111001044385 | 11001 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2775260 | 20234 | 41 | 111001010928 | 11001 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2775264 | 20234 | 26 | 111001044385 | 11001 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2775267 | 20234 | 33 | 111001044385 | 11001 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
423240 rows × 109 columns
Revisamos las nuevas columnas añadidas recientemente.
saber11_n.columnsIndex(['PERIODO', 'PUNT_MATEMATICAS', 'COLE_COD_DANE_SEDE',
'COLE_COD_MCPIO_UBICACION', 'OHE_M', 'OHE_Estrato 2', 'OHE_Estrato 3',
'OHE_Estrato 4', 'OHE_Estrato 5', 'OHE_Estrato 6',
...
'OHE_Todos o casi todos los días', 'OHE_3 a 5 veces por semana',
'OHE_Nunca o rara vez comemos eso', 'OHE_Todos o casi todos los días',
'OHE_Entre 11 y 20 horas', 'OHE_Entre 21 y 30 horas',
'OHE_Menos de 10 horas', 'OHE_Más de 30 horas',
'FAMI_TIENECOMPUTADOR_Si', 'FAMI_TIENEINTERNET_Si'],
dtype='object', length=109)
# Dividir los datos en conjuntos de entrenamiento y prueba
X = saber11_n.drop('PUNT_MATEMATICAS', axis=1)
y = saber11_n['PUNT_MATEMATICAS']# Escalamos la variable charges para hacerla más estandar
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#Los algoritmos de preprocessing de sklearn están preparados para convertir matrices por lo que tenemos que hacer una transformación de nuestra variable y
# ya que es una variable de tipo Series
# para ello hacemos un .to_numpy() que nos convierte la serie en un array y luego hacemos reshape (-1,1) que transforma un array de 1xn en una matriz de nx1
y = scaler.fit_transform(y.to_numpy().reshape(-1,1))
# Volvemos a transformar nuestra variable en un array de 1xn
y=y.reshape(1,-1)[0]# Escalar los datos utilizando MaxAbsScaler
scaler = MaxAbsScaler()
X_scaled = scaler.fit_transform(X)
# preparamos train data y test data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=43)
# Reemplazar NaN con ceros
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)# Crear y entrenar el modelo de regresión lineal múltiple
regresion_lineal=LinearRegression()
regresion_lineal.fit(X_train, y_train)# FASE VALIDACION
# predecimos los valores y para los datos usados en el entrenamiento
prediccion_entrenamiento = regresion_lineal.predict(X_train)
# calculamos el Error Cuadrático Medio (MSE = Mean Squared Error)
mse_hipot5_train = mean_squared_error(y_true = y_train, y_pred = prediccion_entrenamiento)
print('Error Cuadrático Medio (MSE) HIPO 1 TRAIN= ' + str(mse_hipot5_train))
# predecimos los valores y para los datos usados en el entrenamiento
prediccion_entrenamiento = regresion_lineal.predict(X_test)
# calculamos el Error Cuadrático Medio (MSE = Mean Squared Error)
mse_hipot5_test = mean_squared_error(y_true = y_test, y_pred = prediccion_entrenamiento)
print('Error Cuadrático Medio (MSE) HIPO 1 TEST= ' + str(mse_hipot5_test))Error Cuadrático Medio (MSE) HIPO 1 TRAIN= 0.9305982848337508
Error Cuadrático Medio (MSE) HIPO 1 TEST= 0.9253285091410614
# Gráfico de residuos
residuos = y_test - prediccion_entrenamiento
plt.figure(figsize=(8, 6))
plt.scatter(prediccion_entrenamiento, residuos, color='blue', alpha=0.5)
plt.xlabel('Valores Predichos')
plt.ylabel('Residuos')
plt.title('Gráfico de Residuos')
plt.hlines(y=0, xmin=prediccion_entrenamiento.min(), xmax=prediccion_entrenamiento.max(), color='red', linestyle='--', lw=2)
plt.show()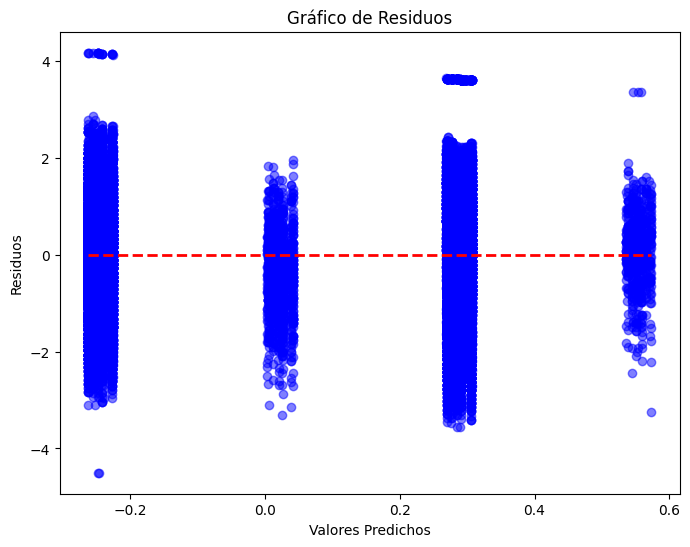
# Importancia de las variables
importancia_variables = pd.DataFrame({'Variable': X.columns, 'Importancia': regresion_lineal.coef_})
importancia_variables = importancia_variables.sort_values(by='Importancia', ascending=False)
plt.figure(figsize=(40, 38))
sns.barplot(x='Importancia', y='Variable', data=importancia_variables)
plt.title('Importancia de las Variables')
plt.xlabel('Importancia')
plt.ylabel('Variable')
plt.show()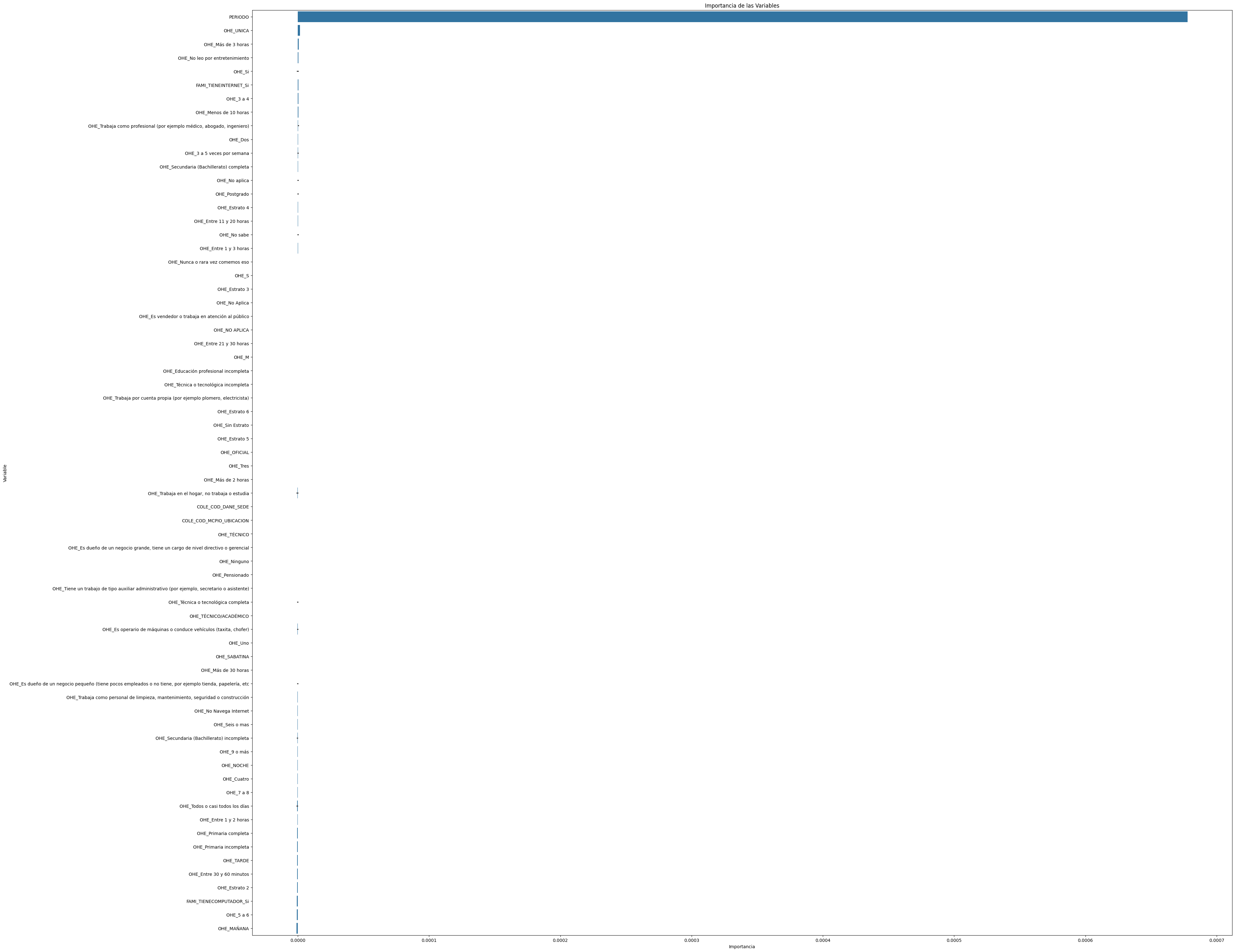
saber11_n['PERIODO'].unique()array([20181, 20182, 20191, 20194, 20201, 20204, 20211, 20214, 20221,
20231, 20234])
# Analizar el impacto del cierre de escuelas por COVID-19
periodos_antes_covid = [20181, 20182,20191, 20194]
periodos_durante_covid = [20201, 20204, 20211, 20214]
periodos_despues_covid = [20221, 20231, 20234, 20234]
datos_antes_covid = saber11_n[saber11_n['PERIODO'].isin(periodos_antes_covid)]
datos_durante_covid = saber11_n[saber11_n['PERIODO'].isin(periodos_durante_covid)]
datos_despues_covid = saber11_n[saber11_n['PERIODO'].isin(periodos_despues_covid)]puntaje_promedio_antes_covid = datos_antes_covid['PUNT_MATEMATICAS'].mean()
puntaje_promedio_durante_covid = datos_durante_covid['PUNT_MATEMATICAS'].mean()
puntaje_promedio_despues_covid = datos_despues_covid['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio antes del COVID-19:", puntaje_promedio_antes_covid)
print("Puntaje promedio durante el COVID-19:", puntaje_promedio_durante_covid)
print("Puntaje promedio después del COVID-19:", puntaje_promedio_despues_covid)Puntaje promedio antes del COVID-19: 54.76147510590245
Puntaje promedio durante el COVID-19: 54.68657360062099
Puntaje promedio después del COVID-19: 55.43896821185664
saber11_n['COLE_COD_DANE_SEDE']| COLE_COD_DANE_SEDE | |
|---|---|
| 266 | 311001042667 |
| 267 | 311001042667 |
| 268 | 311001042667 |
| 269 | 311001042667 |
| 270 | 311001042667 |
| ... | ... |
| 2775242 | 311001005451 |
| 2775259 | 111001044385 |
| 2775260 | 111001010928 |
| 2775264 | 111001044385 |
| 2775267 | 111001044385 |
423240 rows × 1 columns
import geopandas as gpd
from shapely.geometry import Point# localidades de Bogotá D.C
localidades_shp = gpd.read_file("/content/drive/MyDrive/icfes/bogota/localidades.shp")
localidades_shp| OBJECTID | NOMBRE | CODIGO_LOC | DECRETO | LINK | SIMBOLO | ESCALA_CAP | FECHA_CAPT | SHAPE_AREA | SHAPE_LEN | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | SANTA FE | 3 | Acuerdo 117 de 2003 | None | None | None | NaT | 4.517065e+07 | 43779.905440 | POLYGON ((100996.362 103506.019, 101013.606 10... |
| 1 | 11 | PUENTE ARANDA | 16 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.731115e+07 | 17854.555403 | POLYGON ((95475.458 104555.873, 95837.202 1049... |
| 2 | 13 | CIUDAD BOLIVAR | 19 | Acuerdo 14 de 1983 | None | None | None | NaT | 1.299864e+08 | 77732.027669 | POLYGON ((91716.74 100390.427, 91714.771 10033... |
| 3 | 6 | BARRIOS UNIDOS | 12 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.190345e+07 | 13426.542795 | POLYGON ((102251.61 110024.092, 101669.946 106... |
| 4 | 2 | SUBA | 11 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.005606e+08 | 65665.349126 | POLYGON ((103891.168 125935.111, 103894.608 12... |
| 5 | 14 | ANTONIO NARIÑO | 15 | Acuerdo 117 de 2003 | None | None | None | NaT | 4.879543e+06 | 12085.873823 | POLYGON ((94092.947 99681.858, 94269.388 99673... |
| 6 | 20 | CANDELARIA | 17 | Acuerdo 117 de 2003 | None | None | None | NaT | 2.060243e+06 | 7444.083075 | POLYGON ((101257.966 100768.507, 101258.45 100... |
| 7 | 4 | ENGATIVA | 10 | Acuerdo 8 de 1977 | None | None | None | NaT | 3.588097e+07 | 32351.036738 | POLYGON ((94467.113 115606.642, 94463.029 1157... |
| 8 | 5 | FONTIBON | 9 | Acuerdo 8 de 1977 | None | None | None | NaT | 3.328100e+07 | 35674.375625 | POLYGON ((91349.527 113469.012, 91426.279 1134... |
| 9 | 17 | SAN CRISTOBAL | 4 | Acuerdo 117 de 2003 | None | None | None | NaT | 4.909850e+07 | 40291.316126 | POLYGON ((101322.246 98588.942, 101325.293 985... |
| 10 | 8 | TEUSAQUILLO | 13 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.419317e+07 | 16432.566183 | POLYGON ((98204.005 107725.863, 98248.098 1076... |
| 11 | 3 | USAQUEN | 1 | Acuerdo 8 de 1977 | None | None | None | NaT | 6.531573e+07 | 46996.167978 | POLYGON ((102251.61 110024.092, 103089.422 115... |
| 12 | 7 | CHAPINERO | 2 | Acuerdo 8 de 1977 | None | None | None | NaT | 3.815586e+07 | 36833.382799 | POLYGON ((102251.61 110024.092, 102811.332 109... |
| 13 | 18 | USME | 5 | Acuerdo 15 de 1993 | None | None | None | NaT | 2.150664e+08 | 108895.163760 | POLYGON ((94611.356 94313.174, 94612.246 94313... |
| 14 | 19 | SUMAPAZ | 20 | Acuerdo 9 de 1986 | None | None | None | NaT | 7.809523e+08 | 216244.441198 | POLYGON ((92731.192 67235.182, 92781.136 67270... |
| 15 | 16 | RAFAEL URIBE URIBE | 18 | Acuerdo 117 de 2003 | None | None | None | NaT | 1.383408e+07 | 19333.547847 | POLYGON ((94395.307 99591.788, 94424.204 99568... |
| 16 | 15 | TUNJUELITO | 6 | Acuerdo 117 de 2003 | None | None | None | NaT | 9.910940e+06 | 23330.007022 | POLYGON ((93314.583 99851.296, 93993.58 99712.... |
| 17 | 12 | LOS MARTIRES | 14 | Acuerdo 8 de 1977 | None | None | None | NaT | 6.514046e+06 | 11013.197559 | POLYGON ((100522.914 102123.105, 100491.468 10... |
| 18 | 9 | KENNEDY | 8 | Acuerdo 8 de 1977 | None | None | None | NaT | 3.858973e+07 | 31422.417887 | POLYGON ((91005.069 107357.708, 91018.543 1073... |
| 19 | 10 | BOSA | 7 | Acuerdo 14 de 1983 | None | None | None | NaT | 2.393545e+07 | 34117.517640 | POLYGON ((87997.629 105621.791, 88093.812 1053... |
import pickle
import requests
from requests.exceptions import ConnectTimeout
from requests.adapters import HTTPAdaptersession = requests.Session()
connect_timeout = 0.1
read_timeout = 10datos_colegios = {}
localidades_fallidas = []proxies = {
'http': 'http://188.114.96.20:80',
}def obtener_datos_localidad(localidad, datos_colegios):
datos_localidad = saber11_n[saber11_n['COLE_COD_DANE_SEDE'] == localidad]
puntaje_promedio_localidad = datos_localidad['PUNT_MATEMATICAS'].mean()
url = f"https://geoportal.dane.gov.co/laboratorio/serviciosjson/visor_sise/buscadorv2.php?palabra={localidad}"
try:
response = session.get(url, proxies=proxies)
if response.status_code == 200:
data = response.json()
if data["estado"] and len(data["resultado"]) > 0:
resultado = data["resultado"][0]
latitud = resultado["LATITUD"]
longitud = resultado["LONGITUD"]
datos_colegios[localidad] = {
"puntaje_promedio": puntaje_promedio_localidad,
"latitud": latitud,
"longitud": longitud
}
else:
print(f"Error en la solicitud a la API del DANE para el código {localidad}")
except ConnectTimeout:
print(f"Error de ConnectTimeout para la localidad {localidad} e intentos {i}")
localidades_fallidas.append(localidad)localidades = saber11_n['COLE_COD_DANE_SEDE'].unique()
#for localidad in localidades:
# obtener_datos_localidad(localidad, datos_colegios)# Reintentar obtener datos para las localidades fallidas
# for localidad in localidades_fallidas:
# obtener_datos_localidad(localidad, datos_colegios)# Usarse si quiere volver a usar el for
# Guardar los datos en un archivo utilizando pickle
# with open('datos_colegios.pkl', 'wb') as archivo:
# pickle.dump(datos_colegios, archivo)# Cargar los datos desde el archivo utilizando pickle
with open('/content/drive/MyDrive/icfes/datos_colegios.pkl', 'rb') as archivo:
datos_colegios = pickle.load(archivo)len(datos_colegios)1252datolocalidades_shp["area"] = localidades_shp.area
localidades_shp["area"]| area | |
|---|---|
| 0 | 4.517065e+07 |
| 1 | 1.731115e+07 |
| 2 | 1.299864e+08 |
| 3 | 1.190345e+07 |
| 4 | 1.005606e+08 |
| 5 | 4.879543e+06 |
| 6 | 2.060243e+06 |
| 7 | 3.588097e+07 |
| 8 | 3.328100e+07 |
| 9 | 4.909850e+07 |
| 10 | 1.419317e+07 |
| 11 | 6.531573e+07 |
| 12 | 3.815586e+07 |
| 13 | 2.150664e+08 |
| 14 | 7.809523e+08 |
| 15 | 1.383408e+07 |
| 16 | 9.910940e+06 |
| 17 | 6.514046e+06 |
| 18 | 3.858973e+07 |
| 19 | 2.393545e+07 |
localidades_shp["perimetro"] = localidades_shp.boundarylocalidades_shp["NOMBRE"] = localidades_shp.NOMBRElocalidades_shp["centroide"] = localidades_shp.centroidpunto_inicial = localidades_shp["centroide"].iloc[0]localidades_shp["distancia"] = localidades_shp["centroide"].distance(punto_inicial)
localidades_shp["distancia"]| distancia | |
|---|---|
| 0 | 0.000000 |
| 1 | 8721.119096 |
| 2 | 18630.258749 |
| 3 | 9333.201006 |
| 4 | 19231.446216 |
| 5 | 7418.334999 |
| 6 | 3990.679376 |
| 7 | 14611.909834 |
| 8 | 14828.435114 |
| 9 | 6001.140480 |
| 10 | 7584.230824 |
| 11 | 16412.080486 |
| 12 | 5643.472536 |
| 13 | 25477.855485 |
| 14 | 66360.150822 |
| 15 | 9088.162443 |
| 16 | 11276.094681 |
| 17 | 5924.795690 |
| 18 | 13538.483689 |
| 19 | 17825.275539 |
def asignar_categoria(puntaje):
if puntaje <= 49:
return 'Bajo'
elif puntaje >= 50 and puntaje < 60:
return 'Medio'
elif puntaje >= 60 and puntaje <= 70:
return 'Alto'
else:
return 'Muy Alto'colegios_data = pd.DataFrame(datos_colegios).T.reset_index()
colegios_data.columns = ['COLE_COD_DANE_SEDE', 'puntaje_promedio', 'latitud', 'longitud']colegios_data['latitud'] = pd.to_numeric(colegios_data['latitud'])
colegios_data['longitud'] = pd.to_numeric(colegios_data['longitud'])colegios_data['geometry'] = colegios_data.apply(lambda row: Point(row['longitud'], row['latitud']), axis=1)colegios_data['categoria'] = colegios_data['puntaje_promedio'].apply(asignar_categoria)colegios_geo = gpd.GeoDataFrame(colegios_data, geometry='geometry')
colegios_geo.crs = {'init': 'epsg:4326'} # Sistema de coordenadas WGS84localidades_shp = localidades_shp.to_crs(epsg=3116)
colegios_geo = colegios_geo.to_crs(epsg=3116)conteo_categorias = colegios_geo.groupby('categoria').size().reset_index(name='cantidad')colores = {'Bajo': 'red', 'Medio': 'orange', 'Alto': 'lightgreen', 'Muy Alto': 'darkgreen'}fig, ax = plt.subplots(figsize=(62, 48))
localidades_shp.plot(ax=ax, alpha=0.5, edgecolor='black')
for categoria, datos in colegios_geo.groupby('categoria'):
datos.plot(ax=ax, markersize=20, color=colores[categoria], label=categoria)
leyenda_labels = [f"{categoria} ({cantidad})" for categoria, cantidad in zip(conteo_categorias['categoria'], conteo_categorias['cantidad'])]
ax.legend(labels=leyenda_labels, title='Categorías (Cantidad de Colegios)')
ax.set_title('Colegios de Bogotá - Categorías de Puntaje Promedio de Matemáticas')
ax.set_xlabel('Longitud')
ax.set_ylabel('Latitud')
plt.show()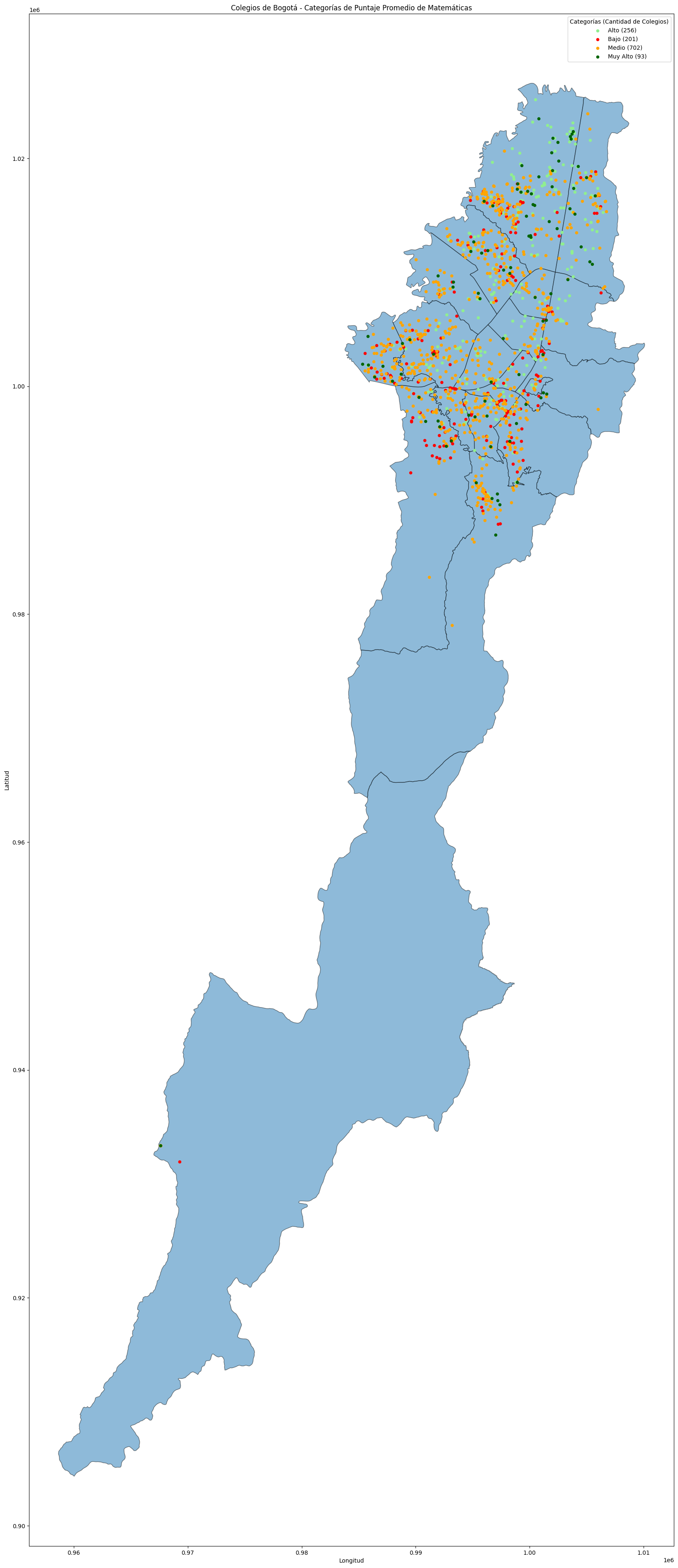
colegios_localidades = gpd.sjoin(colegios_geo, localidades_shp, predicate='within')promedios_localidades = colegios_localidades.groupby('NOMBRE')['puntaje_promedio'].mean().reset_index()promedios_localidades['puntaje_promedio'] = pd.to_numeric(promedios_localidades['puntaje_promedio'], errors='coerce')mejor_localidad = promedios_localidades.loc[promedios_localidades['puntaje_promedio'].idxmax(), 'NOMBRE']
mejor_promedio = promedios_localidades.loc[promedios_localidades['puntaje_promedio'].idxmax(), 'puntaje_promedio']fig, ax = plt.subplots(figsize=(34, 28))
localidades_shp.plot(ax=ax, alpha=0.5, edgecolor='black')
for categoria, datos in colegios_geo.groupby('categoria'):
datos.plot(ax=ax, markersize=20, color=colores[categoria], label=categoria)
leyenda_labels = [f"{categoria} ({cantidad})" for categoria, cantidad in zip(conteo_categorias['categoria'], conteo_categorias['cantidad'])]
ax.legend(labels=leyenda_labels, title='Categorías (Cantidad de Colegios)')
ax.set_title(f'Colegios de Bogotá - Categorías de Puntaje Promedio de Matemáticas
Localidad con mejor promedio: {mejor_localidad} ({mejor_promedio:.2f})')
ax.set_xlabel('Longitud')
ax.set_ylabel('Latitud')
plt.show()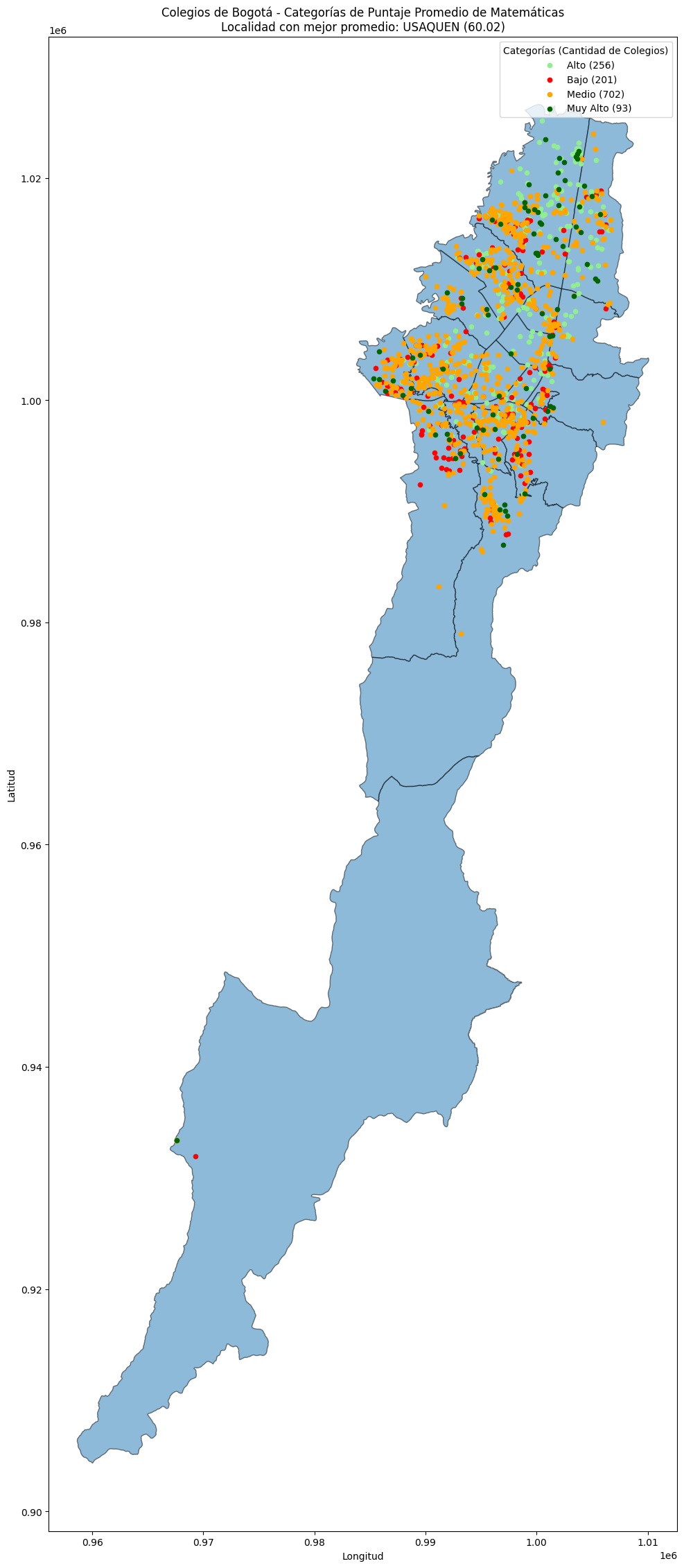
localidades_shp.plot("NOMBRE", figsize=(22, 8))
localidades_shp.head()| OBJECTID | NOMBRE | CODIGO_LOC | DECRETO | LINK | SIMBOLO | ESCALA_CAP | FECHA_CAPT | SHAPE_AREA | SHAPE_LEN | geometry | area | perimetro | centroide | distancia | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | SANTA FE | 3 | Acuerdo 117 de 2003 | None | None | None | NaT | 4.517065e+07 | 43779.905440 | POLYGON ((1000992.557 1003507.35, 1001009.803 ... | 4.517065e+07 | MULTILINESTRING ((100996.362 103506.019, 10101... | POINT (104587.385 99751.307) | 0.000000 |
| 1 | 11 | PUENTE ARANDA | 16 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.731115e+07 | 17854.555403 | POLYGON ((995473.963 1004557.322, 995835.597 1... | 1.731115e+07 | LINESTRING (95475.458 104555.873, 95837.202 10... | POINT (96221.311 102214.378) | 8721.119096 |
| 2 | 13 | CIUDAD BOLIVAR | 19 | Acuerdo 14 de 1983 | None | None | None | NaT | 1.299864e+08 | 77732.027669 | POLYGON ((991716.342 1000393.903, 991714.368 1... | 1.299864e+08 | LINESTRING (91716.74 100390.427, 91714.771 100... | POINT (90628.777 87412.595) | 18630.258749 |
| 3 | 6 | BARRIOS UNIDOS | 12 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.190345e+07 | 13426.542795 | POLYGON ((1002247.94 1010022.688, 1001666.173 ... | 1.190345e+07 | LINESTRING (102251.61 110024.092, 101669.946 1... | POINT (100442.088 108113.433) | 9333.201006 |
| 4 | 2 | SUBA | 11 | Acuerdo 8 de 1977 | None | None | None | NaT | 1.005606e+08 | 65665.349126 | POLYGON ((1003888.431 1025927.164, 1003891.869... | 1.005606e+08 | LINESTRING (103891.168 125935.111, 103894.608 ... | POINT (100186.402 118472.415) | 19231.446216 |
saber11_n.columnsIndex(['PERIODO', 'PUNT_MATEMATICAS', 'COLE_COD_DANE_SEDE',
'COLE_COD_MCPIO_UBICACION', 'OHE_M', 'OHE_Estrato 2', 'OHE_Estrato 3',
'OHE_Estrato 4', 'OHE_Estrato 5', 'OHE_Estrato 6',
...
'OHE_Todos o casi todos los días', 'OHE_3 a 5 veces por semana',
'OHE_Nunca o rara vez comemos eso', 'OHE_Todos o casi todos los días',
'OHE_Entre 11 y 20 horas', 'OHE_Entre 21 y 30 horas',
'OHE_Menos de 10 horas', 'OHE_Más de 30 horas',
'FAMI_TIENECOMPUTADOR_Si', 'FAMI_TIENEINTERNET_Si'],
dtype='object', length=109)
plt.figure(figsize=(10, 6))
sns.boxplot(x='PERIODO', y='PUNT_MATEMATICAS', data=saber11_n)
plt.title('Distribución de puntajes de matemáticas por periodo')
plt.xlabel('Periodo')
plt.ylabel('Puntaje de matemáticas')
plt.show()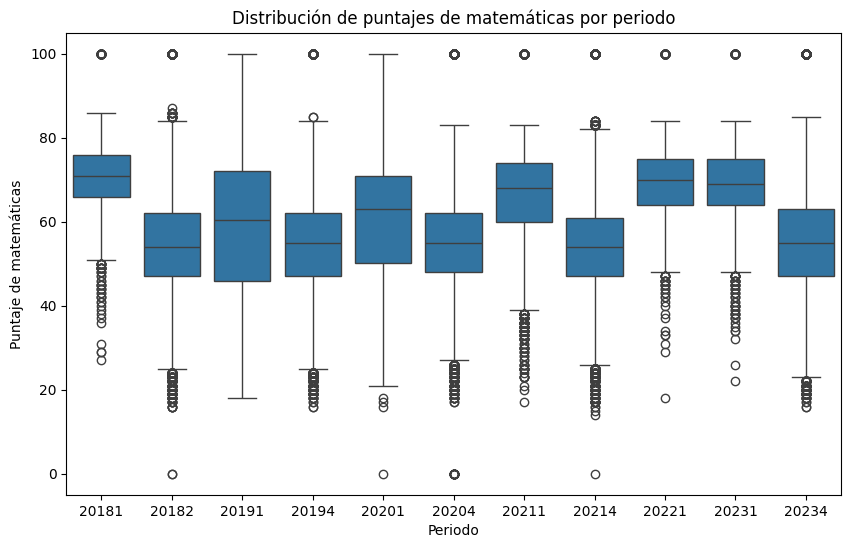
# Seleccionar las columnas binarias asociadas con los estratos socioeconómicos
# columnas_estrato = ['OHE_Estrato 2', 'OHE_Estrato 3', 'OHE_Estrato 4', 'OHE_Estrato 5', 'OHE_Estrato 6', 'OHE_Sin Estrato']
# Crear una nueva columna en el DataFrame que represente el estrato socioeconómico
# saber11_n['Estrato'] = saber11_n[columnas_estrato].idxmax(axis=1)
# # Eliminar las columnas binarias originales
# saber11_n.drop(columns=columnas_estrato, inplace=True)
# Visualizar la distribución de puntajes de matemáticas por estrato socioeconómico
plt.figure(figsize=(10, 6))
sns.boxplot(x='Estrato', y='PUNT_MATEMATICAS', data=saber11_n)
plt.title('Distribución de puntajes de matemáticas por estrato socioeconómico')
plt.xlabel('Estrato socioeconómico')
plt.ylabel('Puntaje de matemáticas')
plt.show()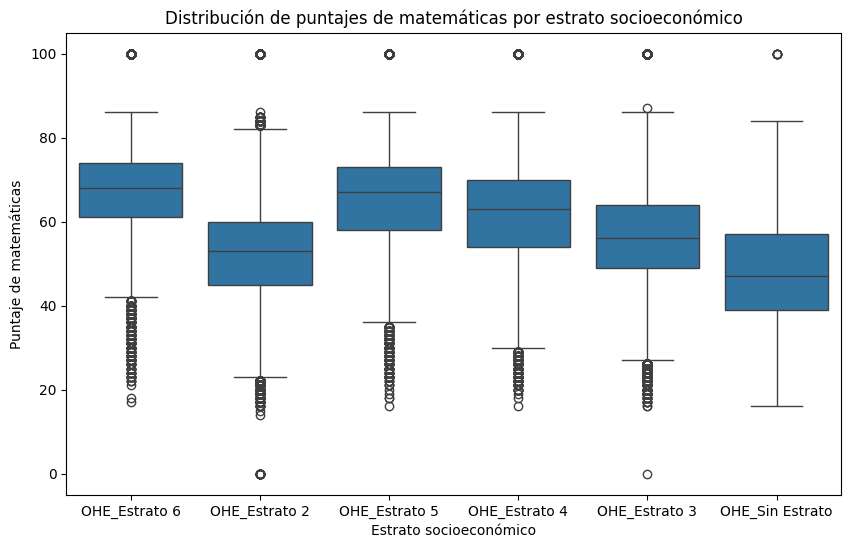
# columnas_jornada = ['OHE_SABATINA', 'OHE_TARDE', 'OHE_UNICA', 'OHE_MAÑANA', 'OHE_NOCHE']
# saber11_n['Jornada'] = saber11_n[columnas_jornada].idxmax(axis=1)
# saber11_n.drop(columns=columnas_jornada, inplace=True)
# Visualizamos la distribución de puntajes de matemáticas por jornada del estudiante
plt.figure(figsize=(10, 6))
sns.barplot(x='Jornada', y='PUNT_MATEMATICAS', data=saber11_n)
plt.title('Distribución de puntajes de matemáticas por jornada del estudiante')
plt.xlabel('Jornada del estudiante')
plt.ylabel('Puntaje de matemáticas')
plt.show()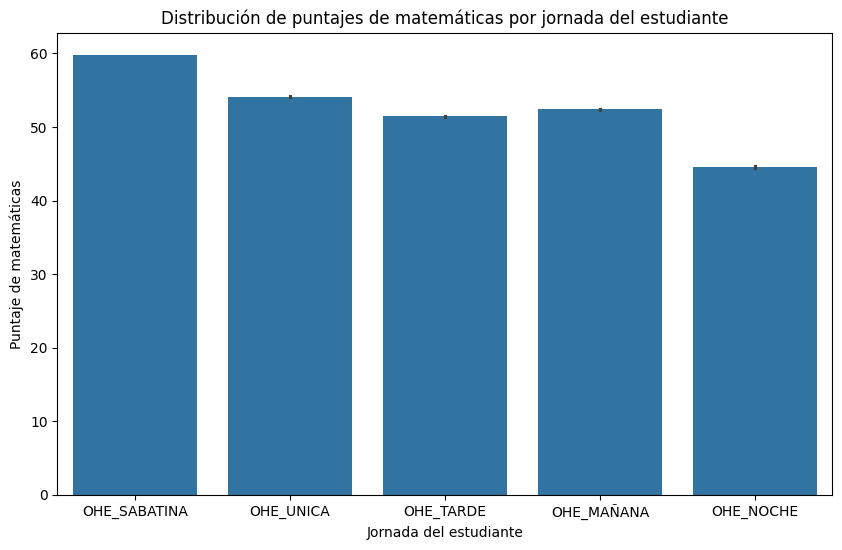
# Calculamos el promedio de los puntajes de matemáticas por estrato
promedio_por_estrato = saber11_n.groupby('Estrato')['PUNT_MATEMATICAS'].mean().reset_index()
# Visualizamos la distribución de puntajes de matemáticas por estrato socioeconómico
plt.figure(figsize=(10, 6))
sns.barplot(x='Estrato', y='PUNT_MATEMATICAS', data=promedio_por_estrato)
plt.title('Promedio de puntajes de matemáticas por estrato socioeconómico')
plt.xlabel('Estrato socioeconómico')
plt.ylabel('Promedio de puntaje de matemáticas')
plt.show()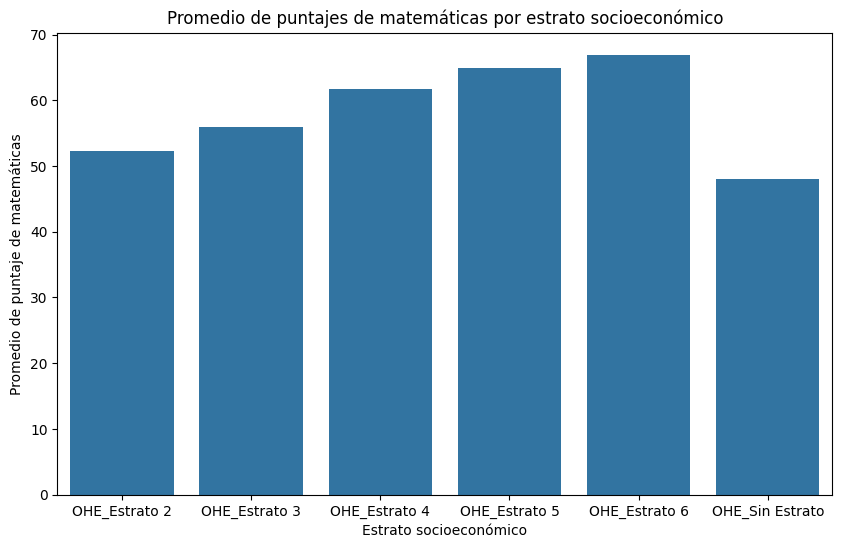
# Calculamos el promedio de los puntajes de matemáticas por estrato y período
promedio_por_estrato_periodo = saber11_n.groupby(['Estrato', 'PERIODO'])['PUNT_MATEMATICAS'].mean().reset_index()
# Visualizamos la distribución de puntajes de matemáticas por estrato socioeconómico y período
plt.figure(figsize=(18, 8))
sns.barplot(x='Estrato', y='PUNT_MATEMATICAS', hue='PERIODO', data=promedio_por_estrato_periodo)
plt.title('Promedio de puntajes de matemáticas por estrato socioeconómico y período')
plt.xlabel('Estrato socioeconómico')
plt.ylabel('Promedio de puntaje de matemáticas')
plt.legend(title='Período', loc='upper left')
plt.show()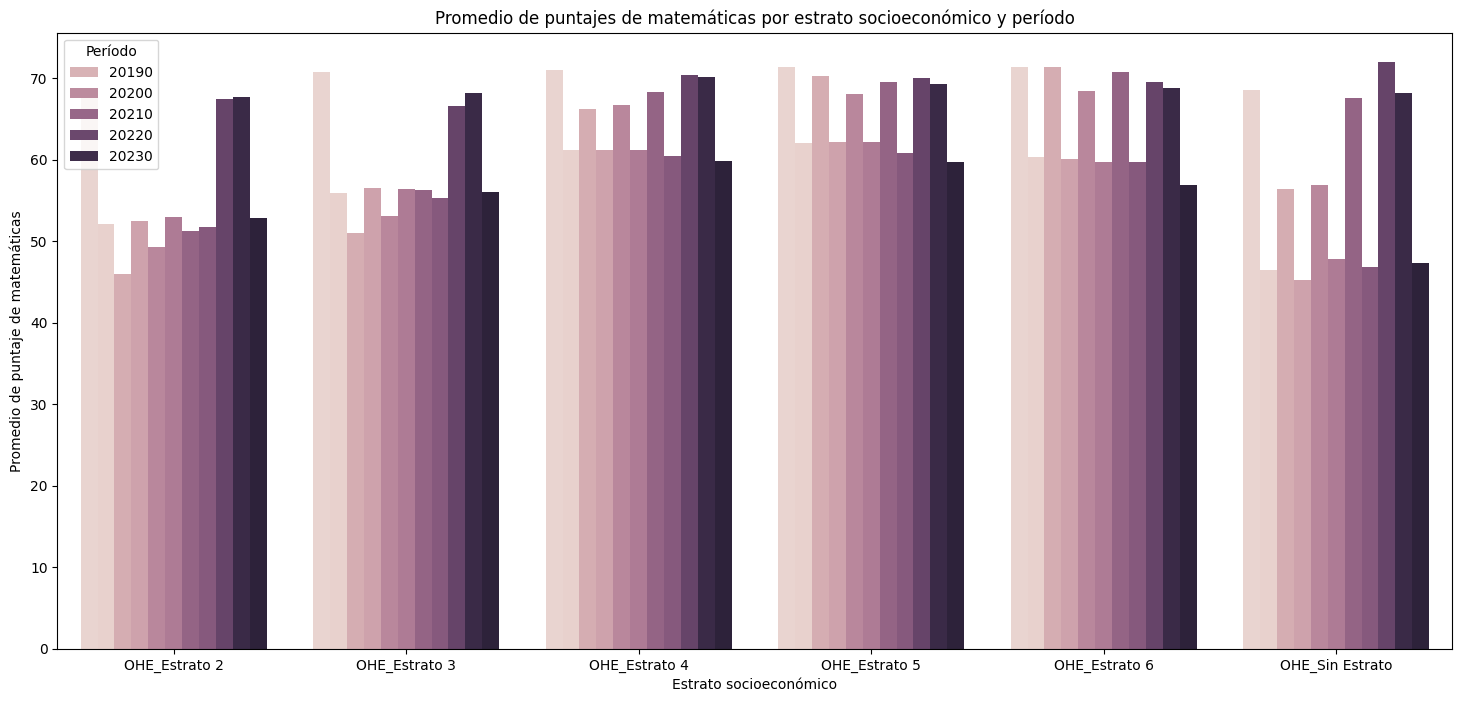
plt.figure(figsize=(8, 6))
sns.boxplot(x='FAMI_TIENECONSOLAVIDEOJUEGOS', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Distribución de puntajes de matemáticas por posesión de consola de videojuegos')
plt.xlabel('Posesión de consola de videojuegos')
plt.ylabel('Puntaje de matemáticas')
plt.show()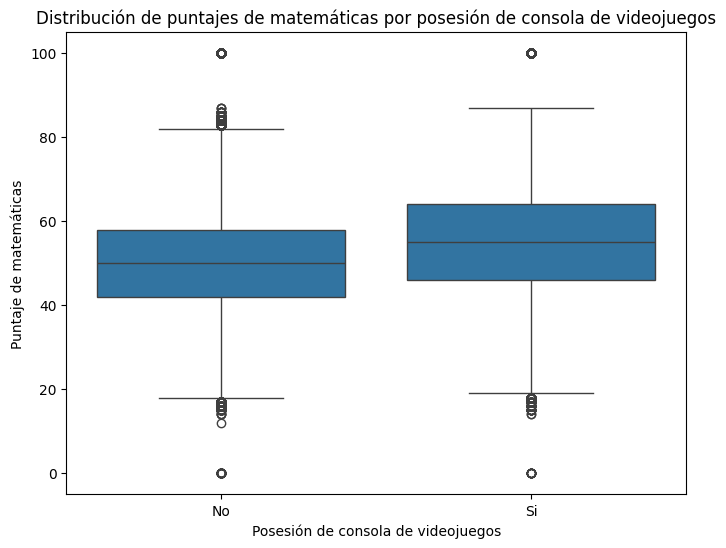
plt.figure(figsize=(8, 6))
sns.barplot(x='FAMI_TIENECONSOLAVIDEOJUEGOS', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean)
plt.title('Promedio de puntajes de matemáticas por posesión de consola de videojuegos')
plt.xlabel('Posesión de consola de videojuegos')
plt.ylabel('Puntaje promedio de matemáticas')
plt.show()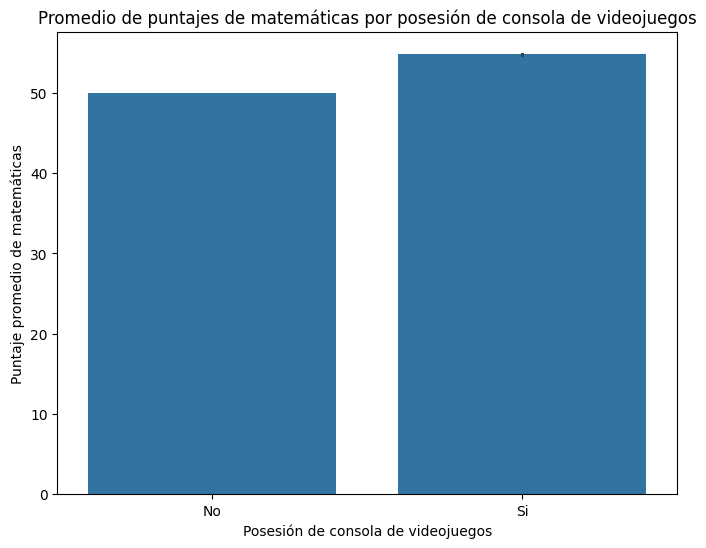
plt.figure(figsize=(8, 6))
sns.barplot(x='FAMI_COMELECHEDERIVADOS', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean)
plt.title('Promedio de puntajes de matemáticas por frecuencia de consumo de leche/derivados')
plt.xlabel('Frecuencia de consumo de leche/derivados')
plt.ylabel('Puntaje promedio de matemáticas')
plt.xticks(rotation=45)
plt.show()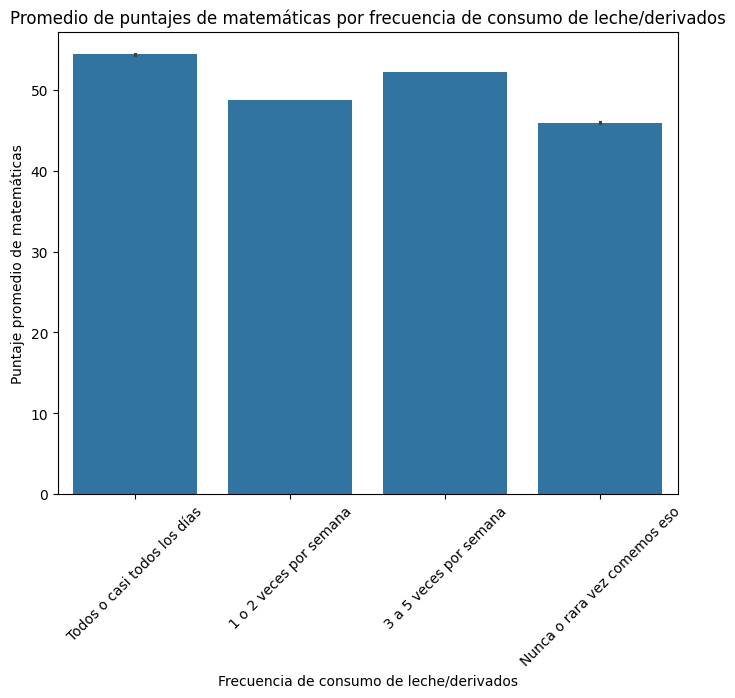
plt.figure(figsize=(8, 6))
sns.barplot(x='FAMI_COMECARNEPESCADOHUEVO', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean)
plt.title('Promedio de puntajes de matemáticas por frecuencia de consumo de carne/pescado/huevo')
plt.xlabel('Frecuencia de consumo de carne/pescado/huevo')
plt.ylabel('Puntaje promedio de matemáticas')
plt.xticks(rotation=45)
plt.show()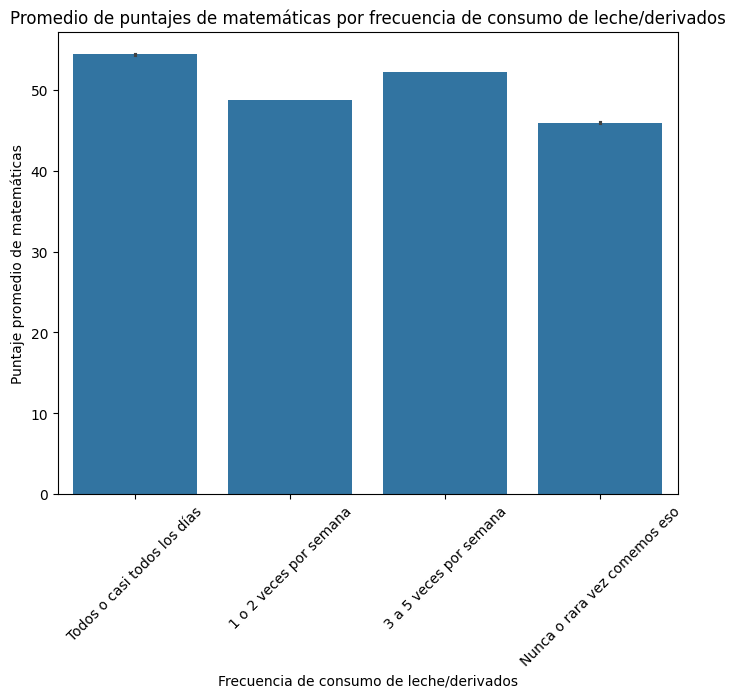
plt.figure(figsize=(10, 6))
sns.barplot(x='ESTU_HORASSEMANATRABAJA', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean)
plt.title('Promedio de puntajes de matemáticas por horas semanales de trabajo del estudiante')
plt.xlabel('Horas semanales de trabajo')
plt.ylabel('Puntaje promedio de matemáticas')
plt.xticks(rotation=45)
plt.show()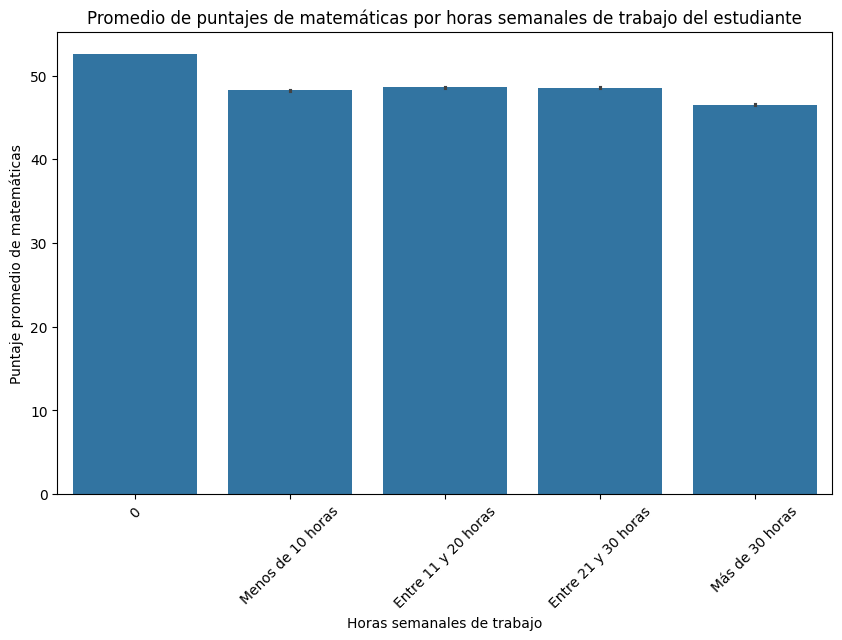
# Obtener las categorías únicas de la situación laboral del padre
categorias_padre = saber11['FAMI_TRABAJOLABORPADRE'].unique()
# Creamos un diccionario para mapear cada categoría a un número
mapeo_categorias_padre = {categoria: i for i, categoria in enumerate(categorias_padre, start=1)}
# Creamos una nueva columna con los números correspondientes a cada categoría
saber11['FAMI_TRABAJOLABORPADRE_NUM'] = saber11['FAMI_TRABAJOLABORPADRE'].map(mapeo_categorias_padre)
plt.figure(figsize=(12, 6))
sns.barplot(x='FAMI_TRABAJOLABORPADRE_NUM', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean, palette='viridis')
plt.title('Promedio de puntajes de matemáticas por situación laboral del padre')
plt.xlabel('Situación laboral del padre')
plt.ylabel('Puntaje promedio de matemáticas')
# Generamos las etiquetas para el eje x
etiquetas_padre = [f"{mapeo_categorias_padre[categoria]}: {categoria}" for categoria in categorias_padre]
plt.xticks(range(len(categorias_padre)), etiquetas_padre, rotation=45, ha='right')
plt.tight_layout()
plt.show()
# Obtener las categorías únicas de la situación laboral del padre
categorias_padre = saber11['FAMI_TRABAJOLABORMADRE'].unique()
# Crear un diccionario para mapear cada categoría a un número
mapeo_categorias_padre = {categoria: i for i, categoria in enumerate(categorias_padre, start=1)}
# Crear una nueva columna con los números correspondientes a cada categoría
saber11['FAMI_TRABAJOLABORPADRE_NUM'] = saber11['FAMI_TRABAJOLABORPADRE'].map(mapeo_categorias_padre)
plt.figure(figsize=(12, 6))
sns.barplot(x='FAMI_TRABAJOLABORPADRE_NUM', y='PUNT_MATEMATICAS', data=saber11, estimator=np.mean, palette='viridis')
plt.title('Promedio de puntajes de matemáticas por situación laboral del padre')
plt.xlabel('Situación laboral del padre')
plt.ylabel('Puntaje promedio de matemáticas')
# Generar las etiquetas para el eje x
etiquetas_padre = [f"{mapeo_categorias_padre[categoria]}: {categoria}" for categoria in categorias_padre]
plt.xticks(range(len(categorias_padre)), etiquetas_padre, rotation=45, ha='right')
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 6))
sns.boxplot(x='ESTU_DEDICACIONLECTURADIARIA', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Distribución de puntajes de matemáticas por dedicación diaria a la lectura')
plt.xlabel('Dedicación diaria a la lectura')
plt.ylabel('Puntaje de matemáticas')
plt.xticks(rotation=45)
plt.show()
# Reflexionar sobre el impacto de la educación remota en estudiantes de colegios públicos
estratos_bajos = ['OHE_Estrato 3','OHE_Estrato 2', 'OHE_Sin Estrato']
datos_estratos_bajos = saber11_n[saber11_n['Estrato'].isin(estratos_bajos)]
puntaje_promedio_estratos_bajos_antes_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_antes_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_durante_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_durante_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_despues_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_despues_covid)]['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio en estratos bajos antes del COVID-19:", puntaje_promedio_estratos_bajos_antes_covid)
print("Puntaje promedio en estratos bajos durante el COVID-19:", puntaje_promedio_estratos_bajos_durante_covid)
print("Puntaje promedio en estratos bajos después del COVID-19:", puntaje_promedio_estratos_bajos_despues_covid)Puntaje promedio en estratos bajos antes del COVID-19: 53.639340206185565
Puntaje promedio en estratos bajos durante el COVID-19: 53.603437790531046
Puntaje promedio en estratos bajos después del COVID-19: 54.07104110750106
# Reflexionar sobre el impacto de la educación remota en estudiantes de colegios públicos
estratos_bajos = ['OHE_Estrato 4','OHE_Estrato 5', 'OHE_Estrato 6']
datos_estratos_bajos = saber11_n[saber11_n['Estrato'].isin(estratos_bajos)]
puntaje_promedio_estratos_bajos_antes_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_antes_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_durante_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_durante_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_despues_covid = datos_estratos_bajos[datos_estratos_bajos['PERIODO'].isin(periodos_despues_covid)]['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio en estratos altos antes del COVID-19:", puntaje_promedio_estratos_bajos_antes_covid)
print("Puntaje promedio en estratos altos durante el COVID-19:", puntaje_promedio_estratos_bajos_durante_covid)
print("Puntaje promedio en estratos altos después del COVID-19:", puntaje_promedio_estratos_bajos_despues_covid)Puntaje promedio en estratos altos antes del COVID-19: 63.445088124110164
Puntaje promedio en estratos altos durante el COVID-19: 62.729665195951206
Puntaje promedio en estratos altos después del COVID-19: 63.41948244601945
# Análisis de diferencias por acceso a computador
datos_con_computador = saber11_n[saber11_n['FAMI_TIENECOMPUTADOR_Si'] == 1]
datos_sin_computador = saber11_n[saber11_n['FAMI_TIENECOMPUTADOR_Si'] == 0]
puntaje_promedio_con_computador = datos_con_computador['PUNT_MATEMATICAS'].mean()
puntaje_promedio_sin_computador = datos_sin_computador['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio con acceso a computador:", puntaje_promedio_con_computador)
print("Puntaje promedio sin acceso a computador:", puntaje_promedio_sin_computador)Puntaje promedio con acceso a computador: 56.113439291435924
Puntaje promedio sin acceso a computador: 49.84799705816064
# Análisis de diferencias por acceso a internet
datos_con_internet = saber11_n[saber11_n['FAMI_TIENEINTERNET_Si'] == 1]
datos_sin_internet = saber11_n[saber11_n['FAMI_TIENEINTERNET_Si'] == 0]
puntaje_promedio_con_internet = datos_con_internet['PUNT_MATEMATICAS'].mean()
puntaje_promedio_sin_internet = datos_sin_internet['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio con acceso a internet:", puntaje_promedio_con_internet)
print("Puntaje promedio sin acceso a internet:", puntaje_promedio_sin_internet)- Puntaje promedio con acceso a internet: 55.66399425631207
- Puntaje promedio sin acceso a internet: 49.57813512929482
estratos_bajos_sin_internet = ['OHE_Estrato 4', 'OHE_Estrato 5', 'OHE_Estrato 6']
datos_estratos_bajos_sin_internet = saber11_n[(saber11_n['Estrato'].isin(estratos_bajos_sin_internet)) & (saber11_n['FAMI_TIENEINTERNET_Si'] == 0)]
# Calcular el puntaje promedio para estos estudiantes
puntaje_promedio_estratos_bajos_sin_internet_antes_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_antes_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_sin_internet_durante_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_durante_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_sin_internet_despues_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_despues_covid)]['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio en estratos altos sin acceso a internet antes del COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_antes_covid)
print("Puntaje promedio en estratos altos sin acceso a internet durante el COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_durante_covid)
print("Puntaje promedio en estratos altos sin acceso a internet después del COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_despues_covid)- Puntaje promedio en estratos altos sin acceso a internet antes del COVID-19: 48.86785714285714
- Puntaje promedio en estratos altos sin acceso a internet durante el COVID-19: 48.38167938931298
- Puntaje promedio en estratos altos sin acceso a internet después del COVID-19: 47.903361344537814
estratos_bajos_sin_internet = ['OHE_Estrato 0', 'OHE_Estrato 3', 'OHE_Estrato 2']
datos_estratos_bajos_sin_internet = saber11_n[(saber11_n['Estrato'].isin(estratos_bajos_sin_internet)) & (saber11_n['FAMI_TIENEINTERNET_Si'] == 0)]
# Calcular el puntaje promedio para estos estudiantes
puntaje_promedio_estratos_bajos_sin_internet_antes_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_antes_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_sin_internet_durante_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_durante_covid)]['PUNT_MATEMATICAS'].mean()
puntaje_promedio_estratos_bajos_sin_internet_despues_covid = datos_estratos_bajos_sin_internet[datos_estratos_bajos_sin_internet['PERIODO'].isin(periodos_despues_covid)]['PUNT_MATEMATICAS'].mean()
print("Puntaje promedio en estratos bajos sin acceso a internet antes del COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_antes_covid)
print("Puntaje promedio en estratos bajos sin acceso a internet durante el COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_durante_covid)
print("Puntaje promedio en estratos bajos sin acceso a internet después del COVID-19:", puntaje_promedio_estratos_bajos_sin_internet_despues_covid)- Puntaje promedio en estratos bajos sin acceso a internet antes del COVID-19: 49.73799030409872
- Puntaje promedio en estratos bajos sin acceso a internet durante el COVID-19: 49.33871276392167
- Puntaje promedio en estratos bajos sin acceso a internet después del COVID-19: 49.98374671176249
Analisis de promedio por localidades. (2023)
# Definir la lista de períodos que deseas conservar (solo 2023)
periodos_2023 = [20231, 20234]
# Filtrar el DataFrame para quedarse solo con los períodos de 2023
saber11_2023 = saber11_n[saber11_n['PERIODO'].isin(periodos_2023)]saber11_2023['PERIODO'].unique()array([20231, 20234])
#datos_colegios_2023 = {}
#localidades = saber11_2023['COLE_COD_DANE_SEDE'].unique()
#for localidad in localidades:
# obtener_datos_localidad(localidad, datos_colegios_2023)# Guardar los datos en un archivo utilizando pickle
#with open('datos_colegios_2023.pkl', 'wb') as archivo:
# pickle.dump(datos_colegios_2023, archivo)# Cargar los datos desde el archivo utilizando pickle
with open('/content/drive/MyDrive/icfes/datos_colegios_2023.pkl', 'rb') as archivo:
datos_colegios_2023 = pickle.load(archivo)localidades_shp["area"] = localidades_shp.area
localidades_shp["perimetro"] = localidades_shp.boundary
localidades_shp["NOMBRE"] = localidades_shp.NOMBRE
localidades_shp["centroide"] = localidades_shp.centroid
punto_inicial = localidades_shp["centroide"].iloc[0]
localidades_shp["distancia"] = localidades_shp["centroide"].distance(punto_inicial)colegios_data = pd.DataFrame(datos_colegios_2023).T.reset_index()
colegios_data.columns = ['COLE_COD_DANE_SEDE', 'puntaje_promedio', 'latitud', 'longitud']colegios_data['latitud'] = pd.to_numeric(colegios_data['latitud'])
colegios_data['longitud'] = pd.to_numeric(colegios_data['longitud'])colegios_data['geometry'] = colegios_data.apply(lambda row: Point(row['longitud'], row['latitud']), axis=1)colegios_data['categoria'] = colegios_data['puntaje_promedio'].apply(asignar_categoria)colegios_geo = gpd.GeoDataFrame(colegios_data, geometry='geometry')
colegios_geo.crs = {'init': 'epsg:4326'} # Sistema de coordenadas WGS84localidades_shp = localidades_shp.to_crs(epsg=3116)
colegios_geo = colegios_geo.to_crs(epsg=3116)colegios_localidades = gpd.sjoin(colegios_geo, localidades_shp, predicate='within')promedios_localidades = colegios_localidades.groupby('NOMBRE')['puntaje_promedio'].mean().reset_index()promedios_localidades['puntaje_promedio'] = pd.to_numeric(promedios_localidades['puntaje_promedio'], errors='coerce')print("Promedio de puntaje de matemáticas por localidad")
for _, row in promedios_localidades.iterrows():
print(f"{row['NOMBRE']}: {row['puntaje_promedio']:.2f}")Promedio de puntaje de matemáticas por localidad
ANTONIO NARIÑO: 54.56
BARRIOS UNIDOS: 57.16
BOSA: 52.93
CANDELARIA: 56.86
CHAPINERO: 57.49
CIUDAD BOLIVAR: 51.84
ENGATIVA: 55.60
FONTIBON: 57.84
KENNEDY: 54.39
LOS MARTIRES: 55.12
PUENTE ARANDA: 56.92
RAFAEL URIBE URIBE: 54.29
SAN CRISTOBAL: 52.16
SANTA FE: 53.11
SUBA: 58.97
SUMAPAZ: 50.88
TEUSAQUILLO: 58.55
TUNJUELITO: 55.00
USAQUEN: 60.26
USME: 52.85
# Creamos las barras horizontales
fig, ax = plt.subplots(figsize=(10, 8))
ax.barh(promedios_localidades['NOMBRE'], promedios_localidades['puntaje_promedio'])
# Configuramos el título y las etiquetas de los ejes
ax.set_title('Promedio de Puntaje de Matemáticas por Localidad en Bogotá en el 2023')
ax.set_xlabel('Puntaje Promedio')
ax.set_ylabel('Localidad')
# Agregar los valores de promedio al final de cada barra
for i, v in enumerate(promedios_localidades['puntaje_promedio']):
ax.text(v + 0.1, i, f'{v:.2f}', va='center')
# Ajustar los márgenes y mostrar el gráfico
fig.tight_layout()
plt.show()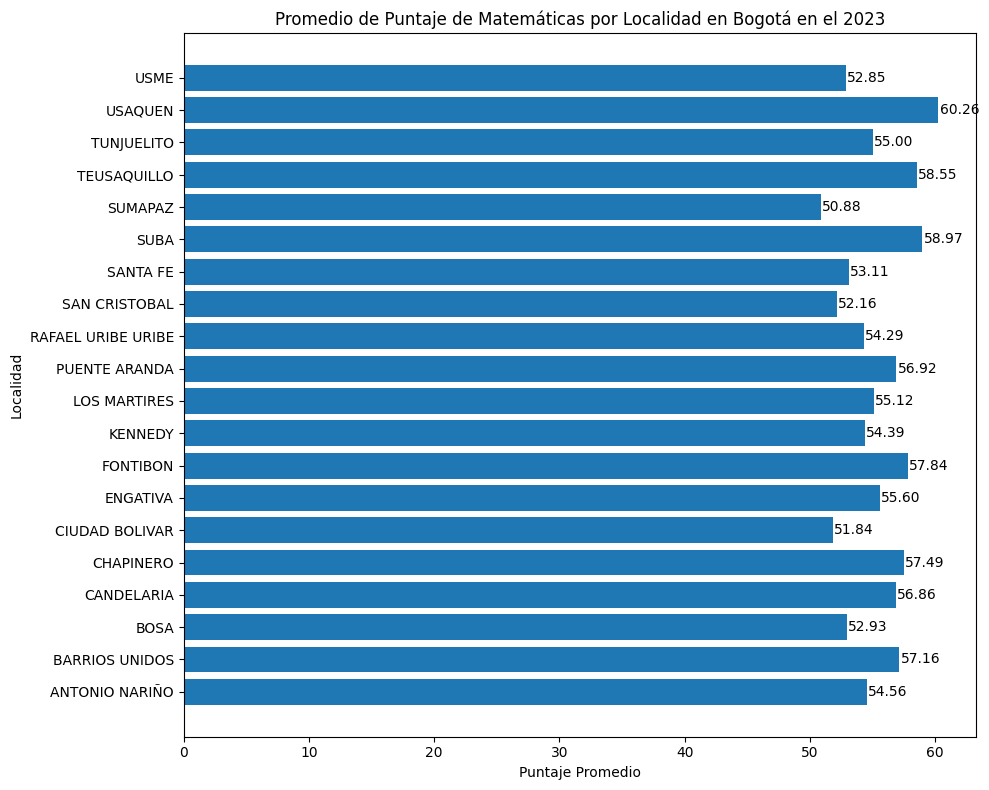
Analisis por encuenta.
Realizaremos un analisis de la encuesta realizada a los profesores de Bogotá. Iremos por las mas importantes, y resolveremos las preguntas respecto al avance que hemos hecho.
df_encuesta = pd.read_csv(path+'encuesta-61-docentes.csv', sep=',', engine='python')
df_encuesta.head()| Género: | Edad: | Nivel de estudios: | Años de experiencia: | Decreto: | CARACTERIZACIÓN DE LA INSTITUCION EDUCATIVA DISTRITAL DONDE LABORA:\n\nNombre de la I.E.D.: | Jornada: | Característica: | Clasificación según área de ubicación: | Localidad: | ... |
|
|
|
| 22. ¿Fueron efectivas dichas medidas? |
|
|
|
|
| |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Femenino | Entre 30 y 40 años | Especialización | Entre 5 y 10 años | 1278 | Pablo Neruda | Mañana | Académico | Urbano | 9 FONTIBON | ... | No | No | Poco accesibles | Obsequio simcard | No fueron efectivas | Estrato 3 | Si, se evidenció una relacion negativa | Influyeron de manera negativa | Influyeron de manera muy negativa | No influyeron |
| 1 | Femenino | < de 30 años | Licenciatura | Entre 10 y 15 años | 1278 | Abel Rodriguez Cespedes | Tarde | Académico | Urbano | 10 ENGATIVA | ... | No | No | Poco accesibles | Tablets | No fueron efectivas | Estrato 3 | Si, se evidenció una relación muy negativa | Influyeron de manera negativa | Influyeron de manera muy negativa | Influyeron de manera negativa |
| 2 | Masculino | > 50 años | Licenciatura | Entre 5 y 10 años | 1278 | La Felicidad IED | Única | Académico | Urbano | 9 FONTIBON | ... | No | Si | Accesibles | Simcard | moderadamente efectivas | Estrato 4 | No hubo relacion alguna | No influyeron | No influyeron | No influyeron |
| 3 | Femenino | Entre 40 y 50 años | Maestria | > 15 años | 1278 | Instituto Técnico Distrital Francisco José de ... | Mañana | Técnico | Urbano | 10 ENGATIVA | ... | No lo se | Si | Poco accesibles | obsequiaron tablets | Levemente efectivas | Estrato 3 | Si, se evidenció una relacion negativa | No influyeron | Influyeron de manera negativa | No influyeron |
| 4 | Masculino | > 50 años | Especialización | > 15 años | 2277 | IED Arborizadora Alta | Tarde | Académico | Urbano | 19 CIUDAD BOLIVAR | ... | No lo se | Si | Poco accesibles | ninguna | No fueron efectivas | Estrato 2 | Si, se evidenció una relación muy negativa | Influyeron de manera negativa | Influyeron de manera muy negativa | Influyeron de manera negativa |
5 rows × 41 columns
df_encuesta.info()Data columns (total 41 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Género: 61 non-null object
1 Edad: 61 non-null object
2 Nivel de estudios: 61 non-null object
3 Años de experiencia: 61 non-null object
4 Decreto: 61 non-null int64
5 CARACTERIZACIÓN DE LA INSTITUCION EDUCATIVA DISTRITAL DONDE LABORA:
Nombre de la I.E.D.: 61 non-null object
6 Jornada: 61 non-null object
7 Característica: 61 non-null object
8 Clasificación según área de ubicación: 61 non-null object
9 Localidad: 61 non-null object
10 1. Durante el cierre de la IED debido a la pandemia por COVID-19 (años 2020 y 2021), los resultados del componente de matemáticas en Saber 11 desmejoraron en comparación a los obtenidos antes del mismo (2019). [2020] 61 non-null object
11 1. Durante el cierre de la IED debido a la pandemia por COVID-19 (años 2020 y 2021), los resultados del componente de matemáticas en Saber 11 desmejoraron en comparación a los obtenidos antes del mismo (2019). [2021] 61 non-null object
12 2. Posteriormente al cierre de la IED debido a la pandemia por COVID-19 (año 2022), los resultados del componente de matemáticas en Saber 11 mejoraron en comparación de los dos años anteriores? (2020 y 2021). 61 non-null object
13 3. Durante el cierre escolar, su IED implementó medidas efectivas para garantizar una transición exitosa hacia la enseñanza en línea. 61 non-null object
14 4. ¿Podría señalar las modalidades o enfoques que adaptó para la enseñanza de matemáticas durante la pandemia de COVID-19 ? (Puede señalar mas de una opción si lo requiere). 61 non-null object
15 5. ¿Cuál o cuales considera que han sido las mas efectivas en relación con su proceso de enseñanza entre 2018 y 2022? (Señale una o varias opciones según lo requiera). 61 non-null object
16 6. ¿Con qué frecuencia realizó encuentros virtuales o clases en línea con sus estudiantes durante el cierre escolar? 61 non-null object
17 7. ¿Cuál considera usted que fue el porcentaje promedio de asistencia de sus estudiantes a los encuentros virtuales o clases en línea que realizó durante el cierre de la IED? 61 non-null object
18 8. ¿Fueron efectivas las estrategias de comunicación que utilizó su IED para llegar a los estudiantes sin acceso a dispositivos electrónicos o internet durante la pandemia de Covid-19? 61 non-null object
19 9. ¿Cómo llevó a cabo la evaluación de los estudiantes con los que no pudo establecer comunicación virtual durante el cierre de la IED? Nombre una o algunas de las estrategias o métodos que utilizó para este propósito." 61 non-null object
20 10. ¿Aumentó el nivel de deserción escolar en su colegio durante la pandemia de COVID-19? 61 non-null object
21 11. ¿Cuáles considera que fueron las principales razones que llevaron a los estudiantes a abandonar la escuela?" (Seleccione todas aquellas que considere). 61 non-null object
22 12. ¿Cambió el porcentaje de reprobación de los estudiantes de su IED durante la pandemia de COVID-19 ? 61 non-null object
23 13. ¿Durante la pandemia, se implementaron políticas de promoción automática o flexibilización de criterios de promoción en su institución educativa? 61 non-null object
24 14. ¿Cree usted, que la promoción de los estudiantes que tuvieron dificultades para participar de las actividades académicas durante los años 2020 y 2021 (a causa del cierre escolar), afectó su desempeño en los resultados del componente de matemáticas de la prueba Saber 11 durante los años 2020, 2021 y 2022? [Saber 2020] 61 non-null object
25 14. ¿Cree usted, que la promoción de los estudiantes que tuvieron dificultades para participar de las actividades académicas durante los años 2020 y 2021 (a causa del cierre escolar), afectó su desempeño en los resultados del componente de matemáticas de la prueba Saber 11 durante los años 2020, 2021 y 2022? [Saber 2021] 61 non-null object
26 14. ¿Cree usted, que la promoción de los estudiantes que tuvieron dificultades para participar de las actividades académicas durante los años 2020 y 2021 (a causa del cierre escolar), afectó su desempeño en los resultados del componente de matemáticas de la prueba Saber 11 durante los años 2020, 2021 y 2022? [Saber 2022] 61 non-null object
27 15. Después de superada la emergencia sanitaria, ¿Considera que las medidas adoptadas en su IED para abordar la pérdida de aprendizaje causada por la pandemia fueron efectivas? 61 non-null object
28 16. Qué estrategias educativas ha implementado para abordar la perdida de aprendizajes debida al cierre de la IED por el COVID-19? 61 non-null object
29 17. ¿Utilizó alguna plataforma o herramienta tecnológica en particular para facilitar la enseñanza de matemáticas en línea? 61 non-null object
30 ¿Cuál o cuales plataformas o herramientas tecnológicas? 61 non-null object
31 18. ¿La SED en general o su IED en particular, ofrecieron programas de capacitación específicos para la enseñanza de las matemáticas en línea durante los años 2020 - 2022? 61 non-null object
32 19. Por su cuenta, ¿Ha participado en programas de capacitación específicos para la enseñanza de matemáticas de manera virtual entre los años 2018-2022? 61 non-null object
33 20. ¿Fueron accesibles los dispositivos tecnológicos de su IED para los docentes y estudiantes durante la pandemia de COVID-19? 61 non-null object
34 21. ¿Qué medidas implementaron el Gobierno Distrital y la SED para garantizar que los estudiantes tuvieran acceso a Internet desde sus hogares? 61 non-null object
35 22. ¿Fueron efectivas dichas medidas? 61 non-null object
36 23. "¿Cuál es el estrato socioeconómico que predomina entre los estudiantes de su Institución Educativa Distrital? 61 non-null object
37 24. ¿Evidenció una relación negativa entre la falta de acceso a recursos tecnológicos y el rendimiento académico de los estudiantes en matemáticas durante la pandemia? 61 non-null object
38 25. ¿Considera que la combinación del contexto socioeconómico de sus estudiantes y la modalidad educativa remota durante la pandemia de COVID -19, influyeron en los resultados obtenidos por ellos en la prueba Saber 11 durante los años 2020 a 2022? [2020] 61 non-null object
39 25. ¿Considera que la combinación del contexto socioeconómico de sus estudiantes y la modalidad educativa remota durante la pandemia de COVID -19, influyeron en los resultados obtenidos por ellos en la prueba Saber 11 durante los años 2020 a 2022? [2021] 61 non-null object
40 25. ¿Considera que la combinación del contexto socioeconómico de sus estudiantes y la modalidad educativa remota durante la pandemia de COVID -19, influyeron en los resultados obtenidos por ellos en la prueba Saber 11 durante los años 2020 a 2022? [2022] 61 non-null object
dtypes: int64(1), object(40)
memory usage: 19.7+ KB
Ahora miremos cuantas filas y columnas hay
df_encuesta.shape61 filas y 47 columnas, es decir, 61 profesores respondieron y hay 40 preguntas que iremos analizando.
df_encuesta = df_encuesta.fillna('No responde')
categorical_columns = ['Género:', 'Edad:', 'Nivel de estudios:', 'Años de experiencia:', 'Jornada:',
'Característica:', 'Clasificación según área de ubicación:', 'Localidad:']
df_encuesta_encoded = pd.get_dummies(df_encuesta, columns=categorical_columns)df_encuesta_encoded| Decreto: | CARACTERIZACIÓN DE LA INSTITUCION EDUCATIVA DISTRITAL DONDE LABORA:\n\nNombre de la I.E.D.: |
|
|
|
|
|
|
|
| ... | Localidad:_18 RAFAEL URIBE URIBE | Localidad:_19 CIUDAD BOLIVAR | Localidad:_2 CHAPINERO | Localidad:_20 SUMAPAZ | Localidad:_3 SANTA FE | Localidad:_4 SAN CRISTOBAL | Localidad:_5 USME | Localidad:_7 BOSA | Localidad:_8 KENNEDY | Localidad:_9 FONTIBON | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1278 | Pablo Neruda | Desmejoraron significativamente | Desmejoraron significativamente | Mejoraron significativamente | Ni de acuerdo, ni en desacuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Ocasionalmente | Entre 50% y 75% | ... | False | False | False | False | False | False | False | False | False | True |
| 1 | 1278 | Abel Rodriguez Cespedes | Desmejoraron levemente | Desmejoraron significativamente | Ni mejoraron, ni desmejoraron | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 2019) | Todos los días | > 75% | ... | False | False | False | False | False | False | False | False | False | False |
| 2 | 1278 | La Felicidad IED | Ni mejoraron, ni desmejoraron | Mejoraron levemente | Ni mejoraron, ni desmejoraron | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Todos los días | > 75% | ... | False | False | False | False | False | False | False | False | False | True |
| 3 | 1278 | Instituto Técnico Distrital Francisco José de ... | Ni mejoraron, ni desmejoraron | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Todos los días | Entre 50% y 75% | ... | False | False | False | False | False | False | False | False | False | False |
| 4 | 2277 | IED Arborizadora Alta | Desmejoraron levemente | Desmejoraron significativamente | Mejoraron levemente | Ni de acuerdo, ni en desacuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | False | True | False | False | False | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 56 | 1278 | COLEGIO ANTONIO NARIÑO (IED) | Mejoraron levemente | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | False | False | False | False | False | False | False | False | False | False |
| 57 | 1278 | COLEGIO COSTA RICA (IED) | Mejoraron levemente | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | False | False | False | False | False | False | False | False | False | True |
| 58 | 1278 | COLEGIO POLICARPA SALAVARRIETA (IED) | Mejoraron levemente | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | False | False | False | False | True | False | False | False | False | False |
| 59 | 1278 | COLEGIO MISAEL PASTRANA BORRERO (IED) | Mejoraron levemente | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | True | False | False | False | False | False | False | False | False | False |
| 60 | 1278 | COLEGIO LA GAITANA (IED) | Mejoraron levemente | Desmejoraron levemente | Mejoraron levemente | De acuerdo | Encuentros virtuales o clases en línea (meet, ... | Presencialidad antes de la pandemia (2018 - 20... | Casi todos los días | Entre 25 y 50% | ... | False | False | False | False | False | False | False | False | False | False |
61 rows × 74 columns
Porcentajes del estado actual de cada profesor.
# Calcular el porcentaje por respuesta para la variable Género
porcentajes_genero = df_encuesta.iloc[:, 0].value_counts(normalize=True) * 100
print("Porcentajes por género de cada profesor:")
for genero, porcentaje in porcentajes_genero.items():
print(f"{genero}: {porcentaje:.2f}%")Porcentajes por género de cada profesor:
- Masculino: 52.46%
- Femenino: 47.54%
# Calcular el porcentaje por respuesta para la variable Edad
porcentajes_edad = df_encuesta.iloc[:, 1].value_counts(normalize=True) * 100
print("Porcentajes por edad de cada profesor:")
for edad, porcentaje in porcentajes_edad.items():
print(f"{edad}: {porcentaje:.2f}%")Porcentajes por edad de cada profesor:
- Entre 30 y 40 años: 36.07%
- Entre 40 y 50 años: 29.51%
-
50 años: 21.31%
- < de 30 años: 13.11%
# Calcular el porcentaje por respuesta para la variable Nivel de estudios
porcentajes_estudios = df_encuesta.iloc[:, 2].value_counts(normalize=True) * 100
print("Porcentajes por nivel de estudio de cada profesor:")
for estudios, porcentaje in porcentajes_estudios.items():
print(f"{estudios}: {porcentaje:.2f}%")Porcentajes por nivel de estudio de cada profesor:
- Maestria: 44.26%
- Especialización: 26.23%
- Licenciatura: 22.95%
- Doctorado: 6.56%
# Calcular el porcentaje por respuesta para la variable Años de experiencia
porcentajes_exp = df_encuesta.iloc[:, 3].value_counts(normalize=True) * 100
print("Porcentajes por experiencia de cada profesor:")
for exp, porcentaje in porcentajes_exp.items():
print(f"{exp}: {porcentaje:.2f}%")Porcentajes por experiencia de cada profesor:
-
15 años: 39.34%
- Entre 5 y 10 años: 27.87%
- Entre 10 y 15 años: 26.23%
- < 5 años: 6.56%
# Calcular el porcentaje por respuesta para la variable Jornada
porcentajes_exp = df_encuesta.iloc[:, 6].value_counts(normalize=True) * 100
print("Porcentajes por experiencia de cada profesor:")
for exp, porcentaje in porcentajes_exp.items():
print(f"{exp}: {porcentaje:.2f}%")Porcentajes por experiencia de cada profesor:
- Mañana: 54.10%
- Tarde: 37.70%
- Única: 8.20%
# Calcular el porcentaje por respuesta para la variable Jornada
porcentajes_localidad = df_encuesta.iloc[:, 9].value_counts(normalize=True) * 100
print("Porcentajes por localidad de cada profesor:")
for localidad, porcentaje in porcentajes_localidad.items():
print(f"{localidad}: {porcentaje:.2f}%")Porcentajes por localidad de cada profesor:
- 9 FONTIBON: 13.11%
- 10 ENGATIVA: 13.11%
- 3 SANTA FE: 9.84%
- 18 RAFAEL URIBE URIBE: 8.20%
- 8 KENNEDY: 8.20%
- 19 CIUDAD BOLIVAR: 6.56%
- 7 BOSA: 6.56%
- 11 SUBA: 4.92%
- 20 SUMAPAZ: 4.92%
- 1 USAQUEN: 3.28%
- 16 PUENTE ARANDA: 3.28%
- 5 USME: 3.28%
- 12 BARRIOS UNIDOS: 3.28%
- 2 CHAPINERO: 3.28%
- 14 LOS MARTIRES: 1.64%
- 4 SAN CRISTOBAL: 1.64%
- 17 LA CANDELARIA: 1.64%
- 15 ANTONIO NARIÑO: 1.64%
- 13 TEUSAQUILLO: 1.64%
Respondiendo segun el analisis las dudas y afirmaciones mas importantes por los profesores.
# Durante el cierre de la IED debido a la pandemia por COVID-19 (años 2020 y 2021),
# los resultados del componente de matemáticas en Saber 11 desmejoraron en comparación
# a los obtenidos antes del mismo (2019).
# Posteriormente al cierre de la IED debido a la pandemia por COVID-19 (año 2022),
# los resultados del componente de matemáticas en Saber 11 mejoraron en comparación
# de los dos años anteriores? (2020 y 2021).
porcentajes_pregunta_01 = df_encuesta.iloc[:, 10].value_counts(normalize=True) * 100
print("Porcentajes de cada profesor a la pregunta: Durante el cierre de la IED debido a la pandemia por COVID-19 (años 2020 y 2021), los resultados del componente de matemáticas en Saber 11 desmejoraron en comparación a los obtenidos antes del mismo (2019):
")
for cierre, porcentaje in porcentajes_pregunta_01.items():
print(f"{cierre}: {porcentaje:.2f}%")
porcentajes_pregunta_02 = df_encuesta.iloc[:, 10].value_counts(normalize=True) * 100
print("
Porcentajes de cada profesor a la pregunta: Posteriormente al cierre de la IED debido a la pandemia por COVID-19 (año 2022), los resultados del componente de matemáticas en Saber 11 mejoraron en comparación de los dos años anteriores? (2020 y 2021).:
")
for cierre, porcentaje in porcentajes_pregunta_02.items():
print(f"{cierre}: {porcentaje:.2f}%")Porcentajes de cada profesor a la pregunta: Durante el cierre de la IED debido a la pandemia por COVID-19 (años 2020 y 2021), los resultados del componente de matemáticas en Saber 11 desmejoraron en comparación a los obtenidos antes del mismo (2019):
- Ni mejoraron, ni desmejoraron: 36.07%
- Mejoraron levemente: 34.43%
- Desmejoraron levemente: 26.23%
- Desmejoraron significativamente: 3.28%
Porcentajes de cada profesor a la pregunta: Posteriormente al cierre de la IED debido a la pandemia por COVID-19 (año 2022), los resultados del componente de matemáticas en Saber 11 mejoraron en comparación de los dos años anteriores? (2020 y 2021).:
- Ni mejoraron, ni desmejoraron: 36.07%
- Mejoraron levemente: 34.43%
- Desmejoraron levemente: 26.23%
- Desmejoraron significativamente: 3.28%
Respondiendo a la primera pregunta desmejoraron significativamente durante el codiv en los años 2020 y 2021 respecto al año 2019.
Respondiendo a la segunda pregunta en el 2022 tuvo un aumento significativo en los primero periodos del año en la hora de apertura y regreso de los estudiantes el cual no se pudo sostener a lo largo de los años.
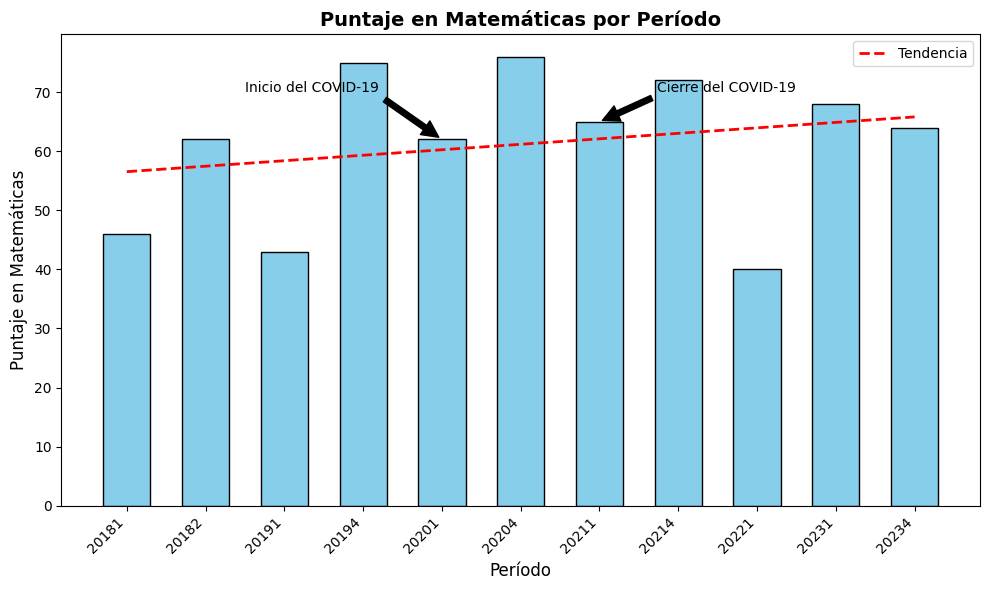
# ¿Podría señalar las modalidades o enfoques que adaptó para la enseñanza de matemáticas
# durante la pandemia de COVID-19? (Puede señalar más de una opción si lo requiere).
porcentajes_pregunta_04 = df_encuesta.iloc[:, 14].value_counts(normalize=True) * 100
print("
Porcentajes de cada profesor a la pregunta: ¿Podría señalar las modalidades o enfoques que adaptó para la enseñanza de matemáticas durante la pandemia de COVID-19? (Puede señalar más de una opción si lo requiere).:
")
for respuesta, porcentaje in porcentajes_pregunta_04.items():
print(f"{respuesta}: {porcentaje:.2f}%")Porcentajes de cada profesor a la pregunta: ¿Podría señalar las modalidades o enfoques que adaptó para la enseñanza de matemáticas durante la pandemia de COVID-19? (Puede señalar más de una opción si lo requiere).:
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc): 60.66%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Entrega de materiales en físico (cartillas, talleres, guías, hojas de trabajo, etc.), Alternancia, Presencialidad posterior a la apertura de las IED: 11.48%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Alternancia: 9.84%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Entrega de materiales en físico (cartillas, talleres, guías, hojas de trabajo, etc.): 6.56%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Presencialidad posterior a la apertura de las IED: 3.28%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Alternancia, Presencialidad posterior a la apertura de las IED: 3.28%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc), Alternancia, Presencialidad posterior a la apertura de las IED: 1.64%
Encuentros virtuales o clases en línea (meet, zoom, teams, etc): 1.64%
Entrega de materiales en físico (cartillas, talleres, guías, hojas de trabajo, etc.): 1.64%```
Vemos que un 96% de los profesores prefieren modalidades virtuales, por preferencia, comodidad, o les resultó lo mejor en lo que podrían ofrecerle a la mayoría de estudiantes. Una de las variables más importantes que afectó en el icfes su rendimiento fue a los estudiantes que no podían conectarse a clases, no tenían internet o donde conectarse (computadora, celular, tablet, etc.). Está variable por debajo del estrato socioeconómico del estudiante, teniendo relación de si pueden o no costearse ese tipo de cosas.
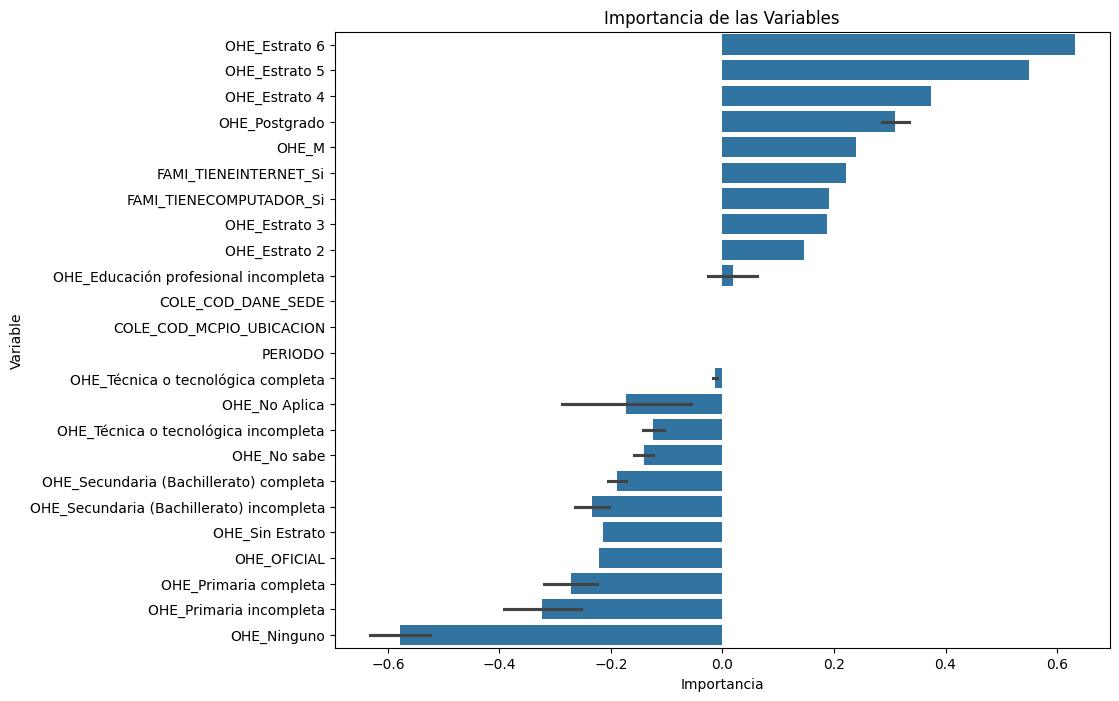
# ¿Cuál o cuáles considera que han sido las más efectivas en relación con su
# proceso de enseñanza entre 2018 y 2022? (Señale una o varias opciones según lo requiera).
porcentajes_pregunta_05 = df_encuesta.iloc[:, 15].value_counts(normalize=True) * 100
print("
Porcentajes de cada profesor a la pregunta: ¿Cuál o cuáles considera que han sido las más efectivas en relación con su proceso de enseñanza entre 2018 y 2022? (Señale una o varias opciones según lo requiera).:
")
for respuesta, porcentaje in porcentajes_pregunta_05.items():
print(f"{respuesta}: {porcentaje:.2f}%")Porcentajes de cada profesor a la pregunta: ¿Cuál o cuáles considera que han sido las más efectivas en relación con su proceso de enseñanza entre 2018 y 2022? (Señale una o varias opciones según lo requiera).:
Presencialidad antes de la pandemia (2018 - 2019): 49.18%
Presencialidad antes de la pandemia (2018 - 2019), Alternancia: 11.48%
Presencialidad antes de la pandemia (2018 - 2019), Alternancia, Presencialidad posterior a la reapertura de las IED (2022): 8.20%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Alternancia: 6.56%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Alternancia, Presencialidad posterior a la reapertura de las IED (2022): 4.92%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Presencialidad posterior a la reapertura de las IED (2022): 4.92%
Presencialidad antes de la pandemia (2018 - 2019), Presencialidad posterior a la reapertura de las IED (2022): 3.28%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc): 3.28%
Encuentros virtuales o clases en línea (meet, zoom, etc): 1.64%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Alternancia, Presencialidad posterior a la reapertura de las IED (2022): 1.64%
Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc): 1.64%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Otras mediaciones pedagógicas virtuales (whatsapp, class room, etc), Alternancia: 1.64%
Presencialidad antes de la pandemia (2018 - 2019), Encuentros virtuales o clases en línea (meet, zoom, etc), Entrega de materiales en físico (cartillas, talleres, guías, hojas de trabajo, etc.): 1.64%
Tenemos un 31% el cual concluye que por falta de conectividad, dispositivos y limitaciones económicas han abandonado las escuelas, para tener certeza de esto trataremos de generar graficas de como afecta al estudiante en el tema material, como economico y en su conectividad en clases. Ademas un punto cruzial es cuantas personas vive el estudiante ya que esto puede afectar en todas las variables.
plt.figure(figsize=(10, 6))
sns.boxplot(x='ESTU_DEDICACIONINTERNET', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Distribución de puntajes de matemáticas por dedicación diaria a internet')
plt.xlabel('Dedicación diaria a internet')
plt.ylabel('Puntaje de matemáticas')
plt.xticks(rotation=45)
plt.show()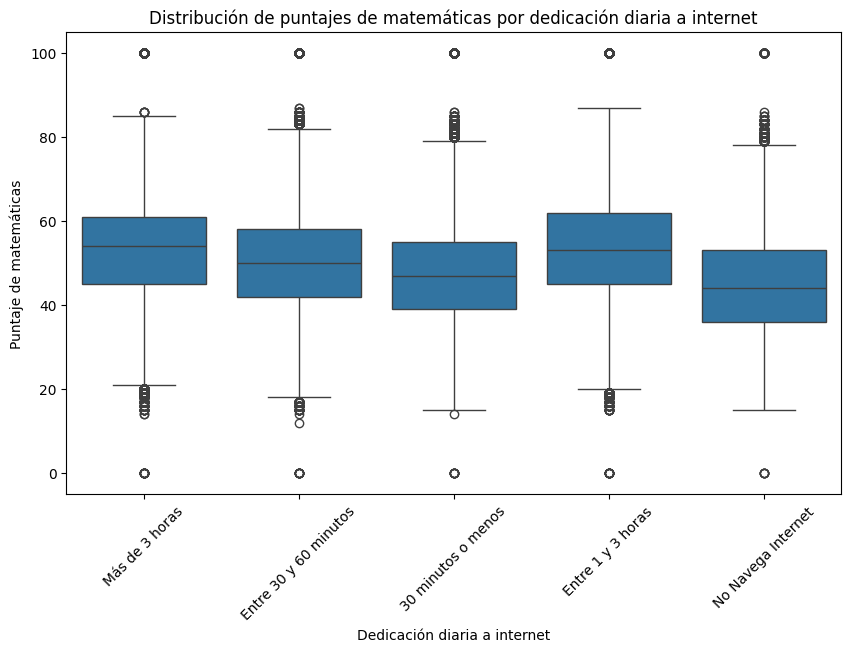
plt.figure(figsize=(10, 6))
sns.barplot(x='ESTU_DEDICACIONINTERNET', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Distribución de puntajes de matemáticas por dedicación diaria a internet')
plt.xlabel('Dedicación diaria a internet')
plt.ylabel('Puntaje de matemáticas')
plt.xticks(rotation=45)
plt.show()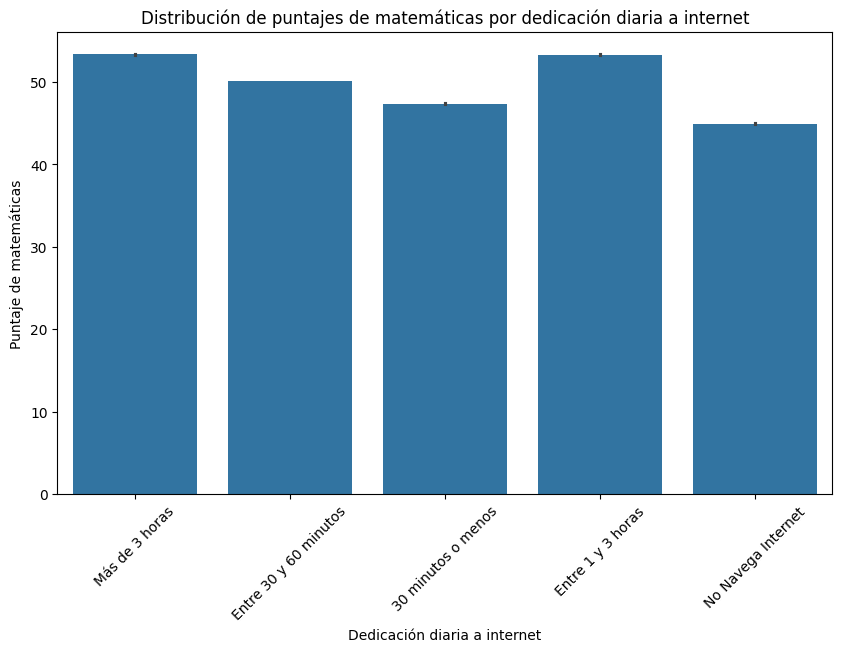
plt.figure(figsize=(8, 6))
sns.barplot(x='FAMI_TIENEINTERNET', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Comparación de puntajes de matemáticas según la disponibilidad de internet en el hogar')
plt.xlabel('Disponibilidad de internet en el hogar')
plt.ylabel('Puntaje de matemáticas')
plt.show()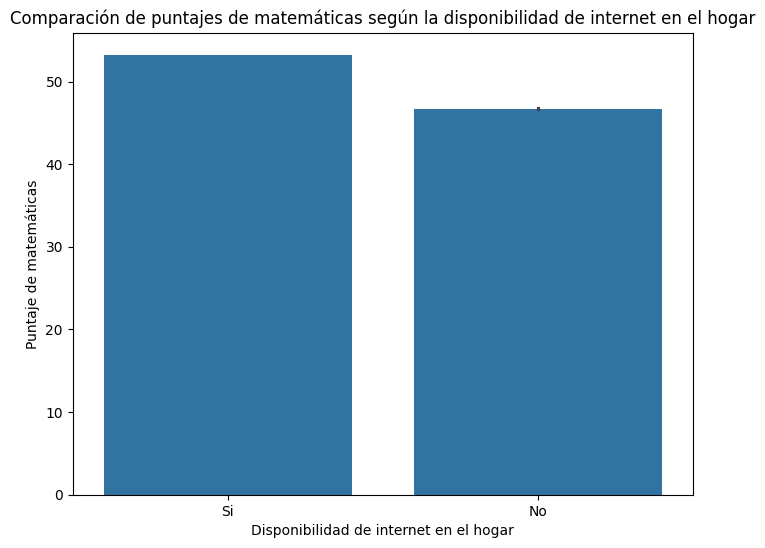
plt.figure(figsize=(10, 6))
sns.barplot(x='FAMI_PERSONASHOGAR', y='PUNT_MATEMATICAS', data=saber11)
plt.title('Relación entre el número de personas en el hogar y el puntaje de matemáticas')
plt.xlabel('Número de personas en el hogar')
plt.ylabel('Puntaje de matemáticas')
plt.xticks(rotation=45)
plt.show()
fig, axs = plt.subplots(2, 2, figsize=(12, 8))
fig.suptitle('Relación entre posesiones en el hogar y puntaje de matemáticas', fontsize=16)
sns.barplot(x='FAMI_TIENELAVADORA', y='PUNT_MATEMATICAS', data=saber11, ax=axs[0, 0])
axs[0, 0].set_title('Lavadora')
axs[0, 0].set_xlabel('Tiene lavadora')
axs[0, 0].set_ylabel('Puntaje de matemáticas')
sns.barplot(x='FAMI_TIENEHORNOMICROOGAS', y='PUNT_MATEMATICAS', data=saber11, ax=axs[0, 1])
axs[0, 1].set_title('Horno/Microondas')
axs[0, 1].set_xlabel('Tiene horno/microondas')
axs[0, 1].set_ylabel('Puntaje de matemáticas')
sns.barplot(x='FAMI_TIENEAUTOMOVIL', y='PUNT_MATEMATICAS', data=saber11, ax=axs[1, 0])
axs[1, 0].set_title('Automóvil')
axs[1, 0].set_xlabel('Tiene automóvil')
axs[1, 0].set_ylabel('Puntaje de matemáticas')
sns.barplot(x='FAMI_TIENEMOTOCICLETA', y='PUNT_MATEMATICAS', data=saber11, ax=axs[1, 1])
axs[1, 1].set_title('Motocicleta')
axs[1, 1].set_xlabel('Tiene motocicleta')
axs[1, 1].set_ylabel('Puntaje de matemáticas')
sns.barplot(x='FAMI_TIENEMOTOCICLETA', y='PUNT_MATEMATICAS', data=saber11, ax=axs[1, 1])
axs[1, 1].set_title('Motocicleta')
axs[1, 1].set_xlabel('Tiene motocicleta')
axs[1, 1].set_ylabel('Puntaje de matemáticas')
sns.barplot(x='FAMI_TIENECOMPUTADOR', y='PUNT_MATEMATICAS', data=saber11, ax=axs[1, 1])
axs[1, 1].set_title('Computador')
axs[1, 1].set_xlabel('Tiene computador')
axs[1, 1].set_ylabel('Puntaje de matemáticas')
plt.tight_layout()
plt.show()